
Polyglot Persistence
Why Polyglot Persistence?
Until recently, most large enterprise applications relied on a single database to store all relevant data. Typically, this will be a relational database like MSSQL, Oracle etc.
Assume the application is an ecommerce platform with thousands of products that have associated images that are stored as binary in a relational database. Is this really a better storage mechanism?
Consider another scenario in which a user visits the same application to look for different products. Is a relational database necessary, or can we use a different database that is search-optimized?
To answer these questions, we must first comprehend the Polyglot Persistence.
Polyglot persistence is a concept of using different data storage technologies to handle varying data storage needs by a single application. Most monolithic applications are now being migrated to microservices. The real difficulty or concern is in designing for data persistence. You can organize the database for your microservice application in two ways.
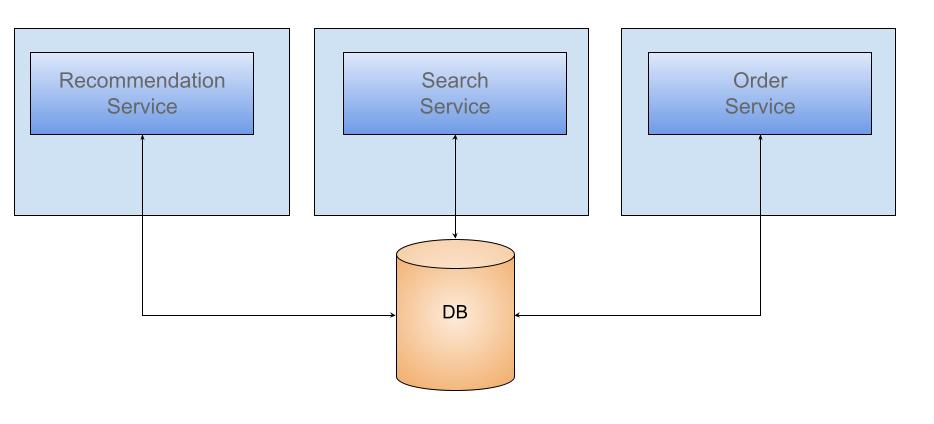
- Shared Database
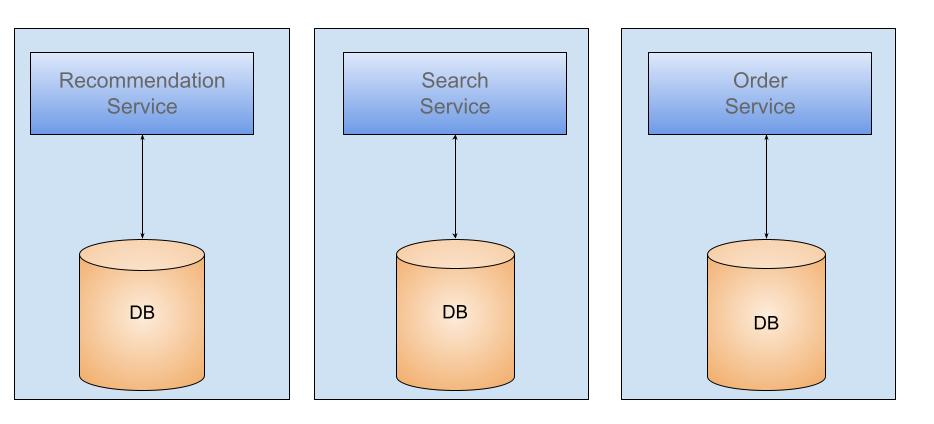
- Database per Service.
 |
 |
The benefits of shared databases include ACID compliance, no latency overhead, and ease of use for developers.
However, there are some drawbacks to using this model.
- Single point of failure
- Runtime coupling
- Design time coupling.
So, having a database per service is the preferred option, but implementing this is not simple because we must consider the following.
- How to handle transactions that span across multiple services?
- How to do joins?
There are numerous best patterns and practices that address the issues listed above like using SAGA pattern, API Composition etc. So, let’s keep going and see how we can implement polyglot persistence for each service.
This can be well explained using an ecommerce application. Let’s consider some of microservice like Recommendation Service, Search Service & Order Service which are part of the ecommerce application.
The following diagram depicts how best storage model looks like for each of these services.
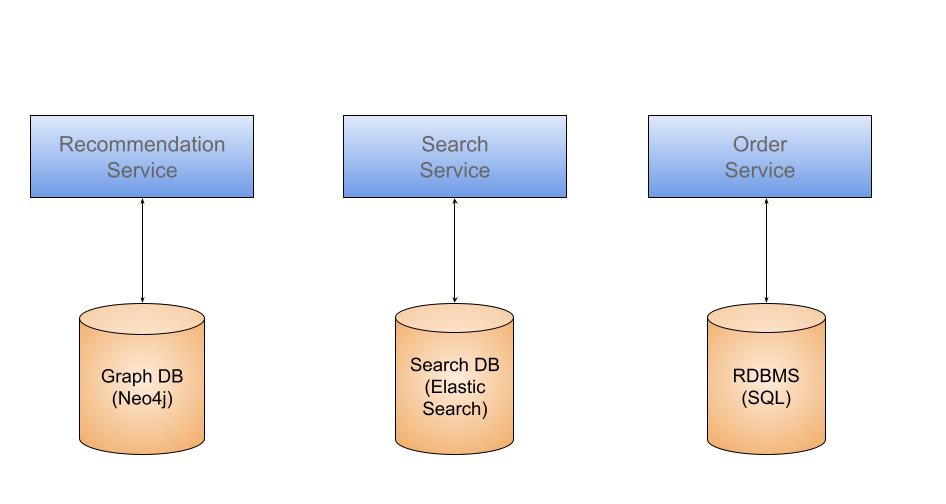
A recommendation service would be best served by a graph database that is optimized for joins across relationships and quick traversal of relationships.
Since the search service is mainly used for querying the preferred solution will be a search database which is optimized for word-based search.
The appropriate database for an order service will be an RDMS because most of them involve business transactions and are also ACID compliant.
Data Storage Types
Polyglot persistence employs a diverse set of data storage types. Here are a few examples:
- Relational (RDBMS)
- Document
- Graph
- Key Value
- Time Series
- Search
- Blob
- Column Store
- NewSQL
Following are some of the use case & example database for each data storage type.
| Data Storage | Use Case(s) | Example Databases |
| Relational (RDBMS) | Transactional updates. Tabular structure data. | SQL /Oracle & Postgre SQL |
| Document | Lots of reads. Infrequent Writes. | MongoDB / Cassandra |
| Graph | Social Networks (Relationships) | Neo4j |
| Key Value | Caching, Configuration | Redis / memcache |
| Time Series | Senor Events (Time based) | kdb /influxDB |
| Search | Searching | Elastic Search/Splunk |
| Blob | Big Files (Storage) | Amazon S3 / Azure Blob |
| Column Store | Analytics | Azamon redshift / Axure SQL data warehouse/ Apache Kudu |
| NewSQL | Globally Distributed | CockroachDB / Google Spanner |
Conclusion
We must first comprehend the nature of the requirement before selecting an appropriate data model. This way, we can be certain that we are not making unending compromises.