
Machine Learning For Fraud Detection in Streaming Services
There are numerous platforms that offer users content streaming and downloads, such as Netflix, Amazon Prime, Disney Hotstar, and the list goes on, with new ones being added on a daily basis. These platforms allow users to stream/download content across a wide range of devices, like mobile phones , laptops, and televisions.
With the increase in usage of the above platforms, there is also a subsequent increase in the number of frauds associated with them. Common frauds that a streaming service faces can be content fraud , streaming fraud, account fraud, and abuse of the terms of service.
Detection and mitigation of fraud and abuse at a large scale and in real time are highly challenging.
In this blog, we will look into Netflix’s fraud and abuse detection framework based on AI data-driven models.

BACKGROUND OF ANOMALY DETECTION
Anomalies (also known as outliers) are defined as certain patterns (or incidents) in a set of data samples that do not conform to an agreed-upon notion of normal behavior in a given context.
An example of an anomaly is if you are a breeder of black dogs and one of your puppies turns out to be pink.
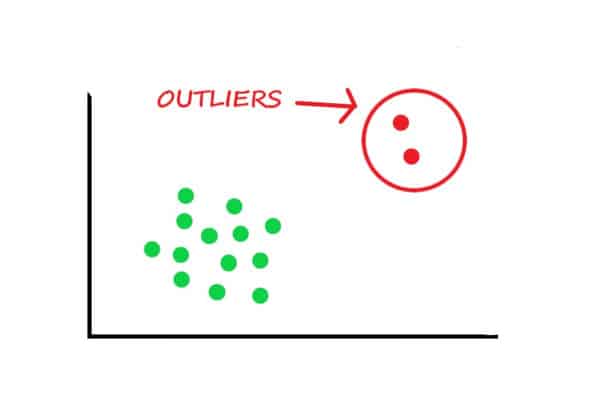
There are two types of Anomaly detection approaches – Rule Based Anomaly Detection and Model Based Anomaly Detection.
Rule-Based Anomaly Detection: This method includes defining a set of rules that are curated by domain experts using their knowledge and experience in the field. They create a list of anomalous incidents that can occur in a specific context and develop methods to mitigate them.
This method includes a domain expert factor, which makes it less reliable and more expensive. We will also have to keep in mind that the set of rules needs to be constantly updated for the expert team to identify novel threats.
Model-Based Anomaly Detection: This method involves the creation of models and using the created models to detect anomalies in a fairly automatic way. A model-based approach is more scalable and suitable for real time analysis.
We must keep in mind that these models rely heavily on context-specific data, which must often be labeled.
There are three major model-based detection approaches:
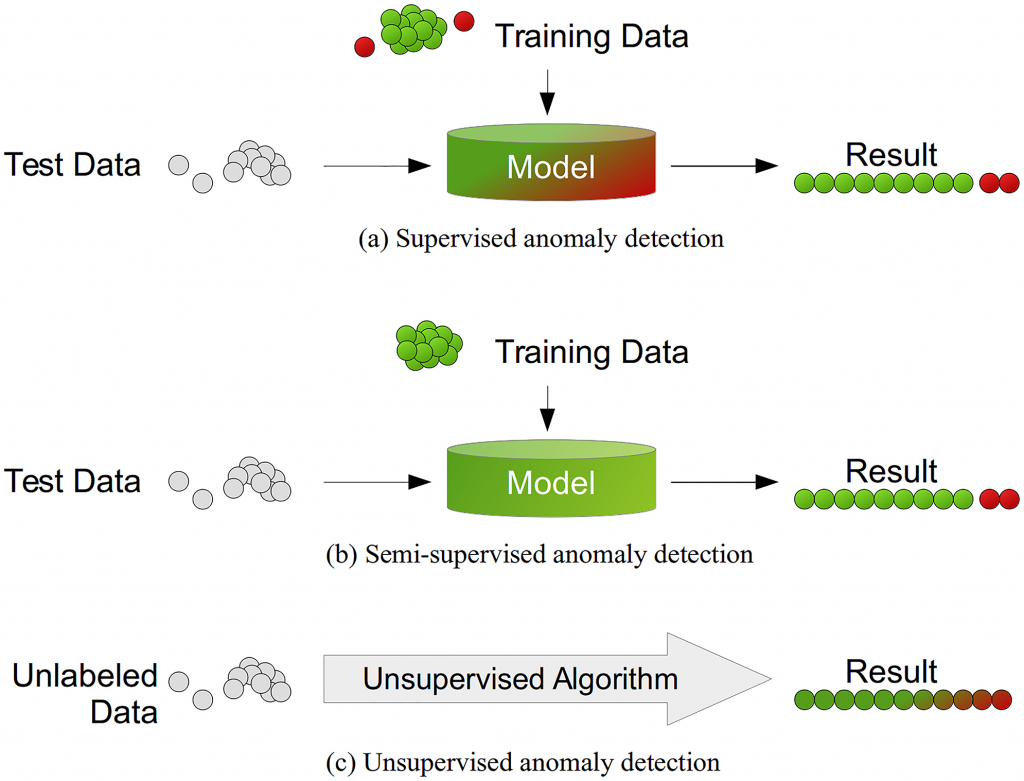
Supervised Detection: Here, we are giving a labelled dataset containing both “Normal” cases and “Anomaly” cases to the model. The created model will be able to detect the cases on the basis of the labelled dataset. This is similar to pattern recognition, but in outlier detection there will be an imbalance between the classes, i.e., there will be a lesser number of “Anomaly” cases as compared to the “Normal” cases in the labelled dataset.
Semi-supervised Detection: In this case, we are only giving “Normal” cases as the input data to the model, and the model will learn from the “Normal” cases given to identify the “Anomaly” cases.
Unsupervised Detection: This method requires no labelled data. It involves detection in “Anomaly” cases based on the intrinsic properties of the data. There is an assumption in this method that the vast majority of instances in the dataset will be “Normal” and the model detects the one that has difficulty fitting in with the rest.
Let’s Talk About Data !
We don’t have a pretrained model or a labelled dataset in this case.So here we use domain specific rule based assumptions to create labels in data.
Here , a set of rule-based heuristics is defined, based on the experience of security experts, to identify anomalous behaviors of clients and label them to create a dataset.
The fraud categories considered by Netflix are: 1. Content Fraud 2. Service fraud; and 3. Account fraud .
Now , Netflix has created a set of heuristic functions with the help of domain experts. Then those functions are used to label the dataset.
In this case, to label the set of normal accounts (non – anomalous cases) , Netflix gathered a set of the most trusted users .
A sample of heuristic functions used by Netflix –
Rapid License Acquisition: A heuristic based on the fact that “normal” users watch one piece of content at a time and take time to move on to another, resulting in a low rate of content license acquisition. So based on that logic , all accounts that acquire licenses at a very high rate are termed “anomalous” accounts.
Large Number of Failed Streaming Attempts: This assumes that a fraudulent account leaves a long trail of errors before streaming a specific piece of content.
Unusual combination of device types and DRMs: DRM – Device Rights Management ensures that the video content is stored and transmitted in an encrypted form so that only the authorized users and devices can play it back. This is based on the fact that a certain device type is matched to a certain DRM system. Unusual combinations can be an indication that the fraud account is trying to bypass security.
We should remember that using heuristic functions can result in false positive incidents, that is there is a chance of wrongly tagging accounts as anomalous.
Data Featurization
Netflix uses 23 data features to develop the detection model. The features mainly belong to two distinct classes. One class accounts for the number of distinct occurrences of a certain parameter/activity/usage in a day. For instance, the dist_title_cnt feature characterizes the number of distinct movie titles streamed by an account. The second class of features on the other hand captures the percentage of a certain parameter/activity/usage in a day.

Label Imbalance Treatment
When there is a class imbalance in the dataset that is in our cases , when the data labelled as “normal”accounts are larger in number than the data labelled for “anomalous” accounts then that can compromise the accuracy of the model .
So Netflix in their algorithm uses a technique called SMOTE – Synthetic Minority Over-sampling Technique that is minority classes get synthetically created

MODEL BASED ANOMALY DETECTION
In this blog we will briefly describe the model based approach that Netflix uses namely 1. Supervised & 2. Semi Supervised
SEMI SUPERVISED ANOMALY DETECTION
The major task of semi supervised anomaly detection model is to learn in the training stage on how the “normal” accounts are distributed . As a result when it comes to the detection stage it can look out for the ones that don’t fall into the range that is learned by the model .
This type of training with one labeled class is called one class method .
Netflix used various one class methods like One Class SVM , Isolation Forest Elliptic Envelope and Local Outlier Factor Approach.
One Class SVM – One Class Support Vector Machine : As discussed above , it does not have labels for all the data , It learns the boundary of normal data point and identifies the data outside the border to be anomalies
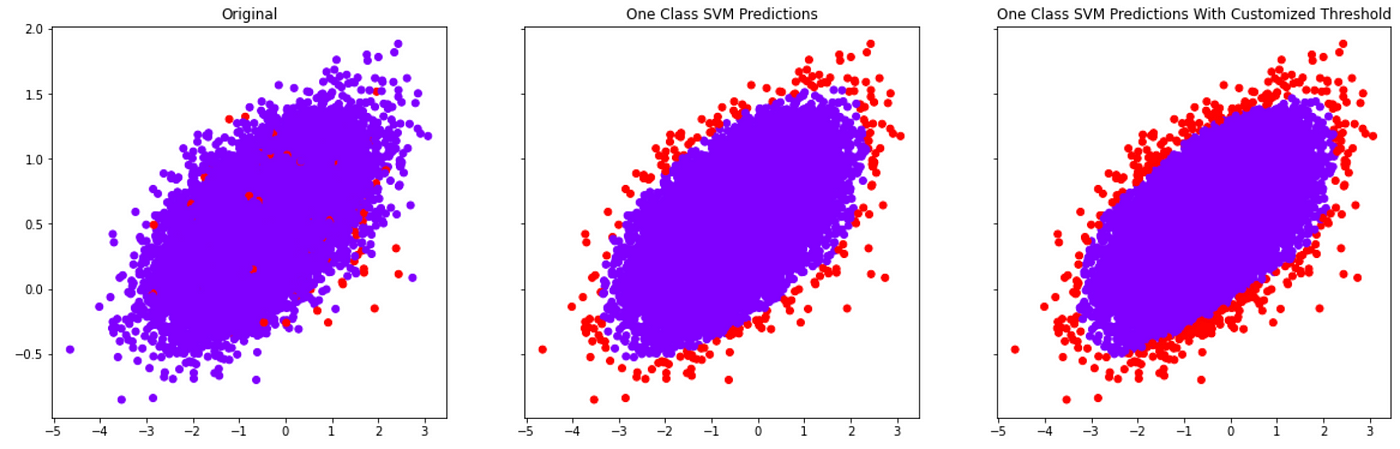
SUPERVISED ANOMALY DETECTION
Binary Classification – In binary classification , we are taking in consideration only two classes – Normal and Anomalous , we are not considering the sub categories of anomalous cases like Account Fraud , Content Fraud and Service Fraud
For the binary classification task Netflix uses multiple supervised classification approaches, namely,
(i) Support Vector Classification (SVC),
(ii) K-Nearest Neighbors classification,
(iii) Decision Tree classification,
(iv) Random Forest classification
(v) Gradient Boosting
(vi) AdaBoost
(vii) Nearest Centroid classification
(viii) Quadratic Discriminant Analysis (QDA) classification
(ix) Gaussian Naive Bayes classification
(x) Gaussian Process Classifier
(xi) Label Propagation classification
(xii) XGBoost
OBSERVATIONS AND DISCUSSIONS
Netflix observed predominant dependence to one of more factors for specific fraud categories.
For the Content Fraud Category, the three most important features are the count of distinct encoding formats (dist_enc_frmt_cnt), the count of distinct devices (dist_dev_id_cnt), and the count of distinct DRMs (dist_drm_cnt). This implies that for content fraud the uses of multiple devices, as well as encoding formats, stand out from the other features.
For the Service Fraud Category ,the three features that it primarily depends upon is the count of content licenses associated with an account (license_cnt), the count of distinct devices (dist_dev_id_cnt), and the percentage use of type (a) devices by an account (dev_type_a_pct). This shows that in the service fraud category the counts of content licenses and distinct devices of type (a) stand out from the other features
For the Account Fraud Category , the count of distinct devices (dist_dev_id_cnt) dominantly stands out from the other features.
Netflix is rolling out a new terms of use that limits the password sharing to a particular household. That is people who are using (“sharing”) one Netflix account from different locations will be affected.
Let’s see how it goes !
References
- Machine Learning for Fraud Detection in Streaming Services – Netflix Technology Blog – https://netflixtechblog.com/machine-learning-for-fraud-detection-in-streaming-services-b0b4ef3be3f6
- One Class SVM for Anomaly Detection – https://medium.com/grabngoinfo/one-class-svm-for-anomaly-detection-6c97fdd6d8af
- Abuse and Fraud Detection in Streaming Services Using Heuristic-Aware Machine Learning- https://arxiv.org/abs/2203.02124