
Large Language Models : Fight them or join them?
The Internet is abuzz with keywords like ChatGPT, Bard, LLaMA, etc. A major chunk of the discussion is focused on how “smart conversational AI models” can make people obsolete and take over tasks like programming. This post is an attempt to understand what happens behind the scenes and make some inferences on how they will impact processes as we see today.
A quick background

Text and voice inputs are considered revolutionary in user interaction designs, since it improves usability and accessibility of the application by adopting spoken language rather than predefined input patterns. Since spoken language cannot be exhaustively represented by a series of patterns, the functionality of such mechanisms have limitations. This is remedied by the use of machine learning models that perform Natural Language Processing in order to create Conversational AI tools (commonly called chat bots).
According to IBM, “Conversational artificial intelligence (AI) refers to technologies, like chatbots or virtual agents, which users can talk to. They use large volumes of data, machine learning, and natural language processing to help imitate human interactions, recognizing speech and text inputs, and translating their meanings across various languages.” They broadly separate the process into four steps.
- Input generation – User gives an input statement as text or voice via a suitable UI.
- Input analysis – Perform NLU (Natural Language Understanding) to understand the input sentence by extracting the lexemes and their semantics. If the input is by voice, speech recognition is also required. This step results in identifying the intention of the user.
- Dialogue management – Formulate an appropriate response using NLG (Natural Language Generation).
- Reinforcement learning – Improve the model by continuously taking feedback.
NLU and NLG has nowadays moved beyond regular ML into the domain of LLMs (Large Language Models) that denote complex models trained on massive volumes of language data. LLMs are now defined for conversations, technical support, or even simple reassurance.
Large Language Models – What are they?
As mentioned before, LLMs denote complex NLU+NLG models that have been trained on massive volumes of language data. NVIDIA considers it as “a major advancement in AI, with the promise of transforming domains through learned knowledge.” It lists the general scope of such LLMs as:
- Text generation for content copyrighting
- Summarization
- Image generation
- Chatbots
- Generating code in different programming languages for function templating
- Translation
They estimate that LLM sizes have been growing 10x annually for the last few years. Some popular models in use are GPT, LaMDA, LLaMA, Chinchilla, Codex, and Sparrow. Nowadays, LLMs are being further refined using domain-specific training for better contextual alignment. Examples of the same are NVIDIA BioNeMo and Microsoft’s BioGPT.
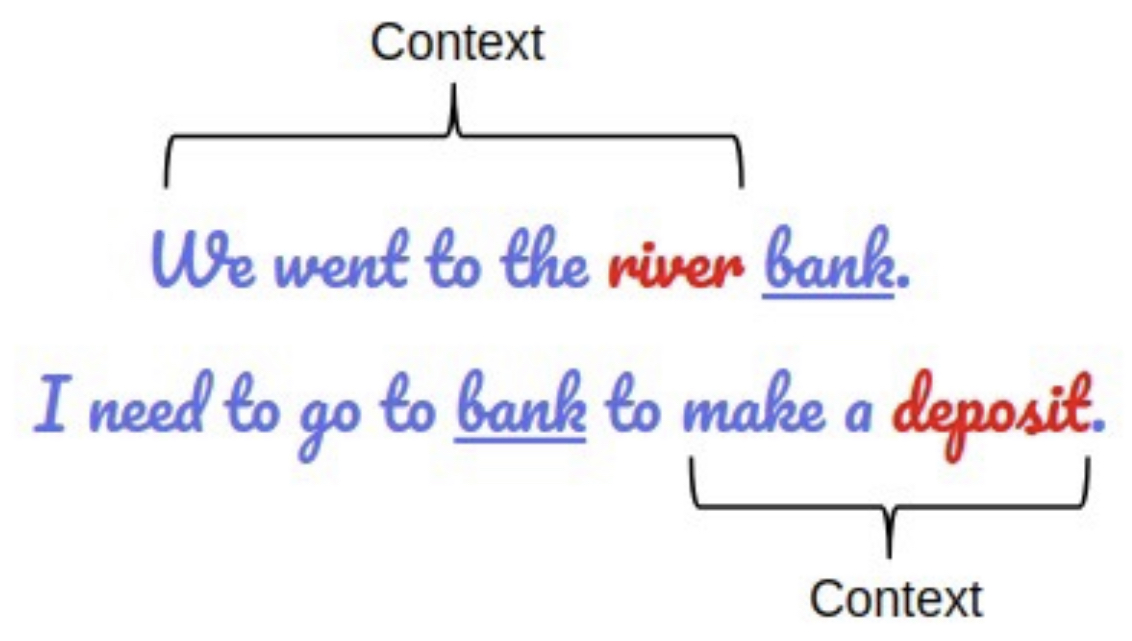
LLMs work predominantly by understanding the underlying context within sentences. Nowadays the implementation is dominated by the use of transformers, which extract context using a process called “attention”. The importance of generating the context is illustrated below, where it is critical to identify the meaning of the word “bank”.
In the upcoming sections, we will explore four models which changed the public landscape of LLMs, followed by a training framework provided by NVIDIA.

GPT 3.5 – Powering ChatGPT
GPT stands for Generative Pre-trained Transformer, an NLG model based on deep learning. Given an initial text as prompt, it will keep predicting the next token in the sequence, thereby generating a human-like output. Transformers use attention mechanisms to maintain contextual information for the input text. GPT 3 is a decoder-only transformer network with a 2048-token context and 175 billion training parameters. It needs a total of 800 GB to store. GPT 3.5 is an enhancement of GPT 3 with word-level filters to remove toxic words.
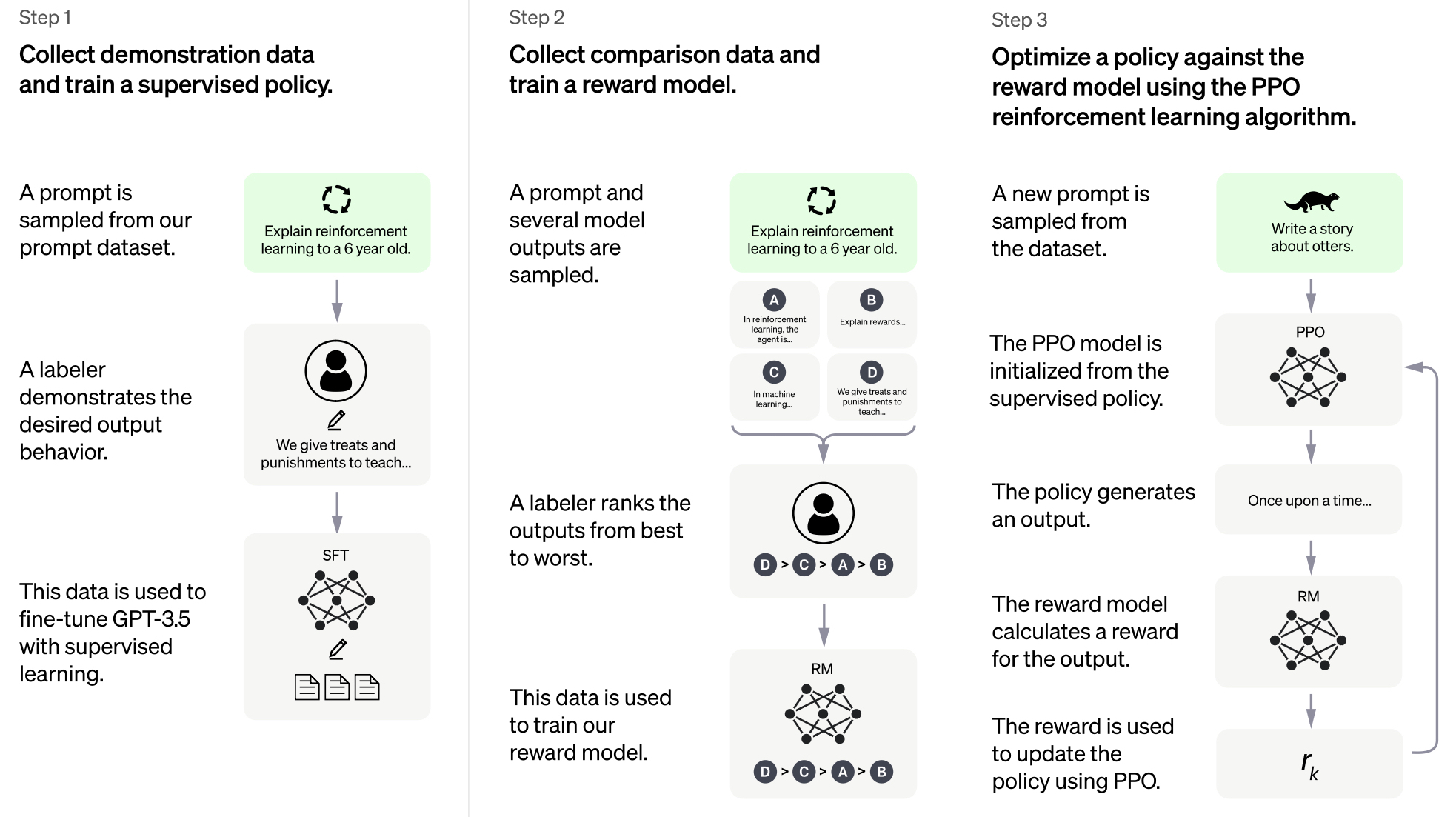
ChatGPT is an initiative of OpenAI (backed by Elon Musk and invested upon by Microsoft) that forms a chat-based conversational front end to GPT 3.5. The model used for this purpose is named Davinci, which was trained using RLHF (Reinforcement Learning from Human Feedback), tuned by PPO (Proximal Policy Optimization). The process followed by RLHF+PPO is given in the illustration below.
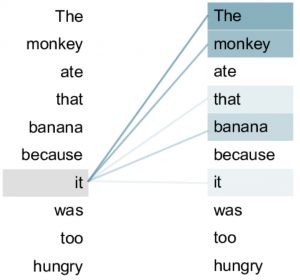
The working of transformer models is based on judging the significance of each part (or token) of the input. In order to do that, the entire input is taken together (which is possible in platforms like ChatGPT since the input is completely available in the prompt). An example is given below, where the term “it” has to choose between the monkey and that banana to set the context.
A detailed explanation of the model is available in “Improving Language Understanding by Generative Pre-Training” by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. As mentioned before, GPT 3 works on a 2048-token context. Hence it is necessary to pad the input appropriately towards the right.
OpenAPI has released its APIs for ChatGPT for further development and use.
LaMDA – The model behind Bard
LaMDA stands for “Language Model for Dialogue Applications”. It is another model that is based upon the concept of transformers (The concept of transformers itself was developed by Google back in 2017, but OpenAI released it as an application first!). The project was announced by Google in 2021.
Contrary to regular transformer models, Google trained its model entirely on dialogue. Hence it is potentially able to create better context for conversational purposes, rather than limiting itself to fully structured sentences. LaMDA training process is split into two phases : pre-training and fine-turning. Pre-training was done on a corpus comprised of more than 1.56 trillion words, leveraging the vast search query database available within Google. This allows LaMDA to create a number of candidate answers for each input dialogue. This is then ranked in the fine-tuning phase to create the best answer. The entire model is monitored based on the aspects of quality (similarity to human language output), safety (causes no harm or bias), and groundedness (answers verifiable with openly available facts).
The entire background of LaMDA is available in “LaMDA: Language Models for Dialog Applications” by Romal Thoppilan et al. A simple example extracted from the paper is given below.
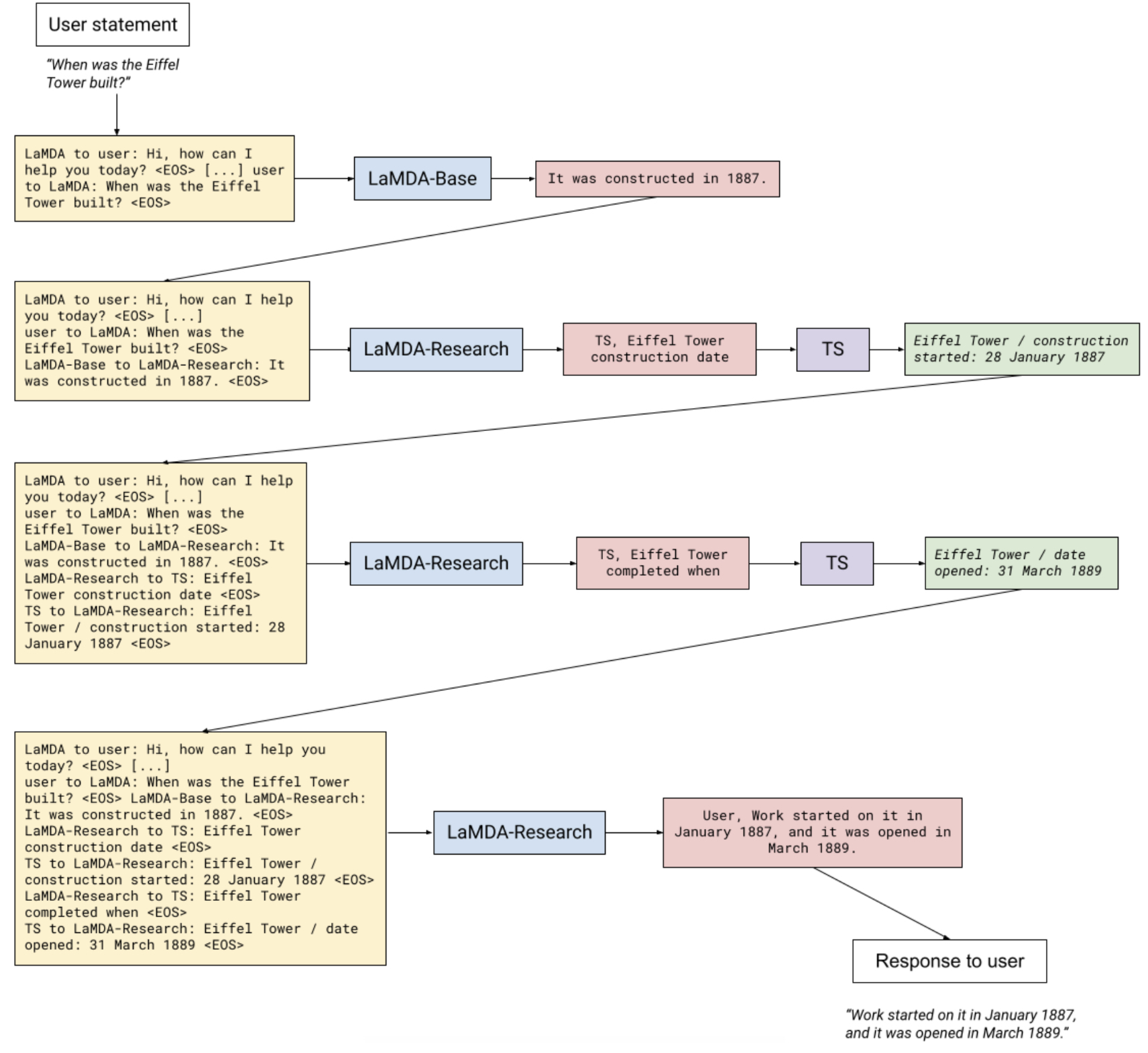
LaMDA is gearing up for a closed-group release for further fine-tuning.
Amazon joins the bandwagon
Amazon developed a LLM using the “chain of thought” philosophy and has been successful in exceeding the performance of GPT 3.5 by more than 15%. The CoT prompting approach integrates language and vision through a two-stage architecture that distinguishes between generating rationalities and inferring answers. Given the inputs in different modalities, Multimodal-CoT decomposes multi-step problems into intermediate reasoning steps (rationale) and then infers the answer. It is demonstrated in “Multimodal Chain-of-Thought Reasoning in Language Models” by Zhuosheng Zhang et al.
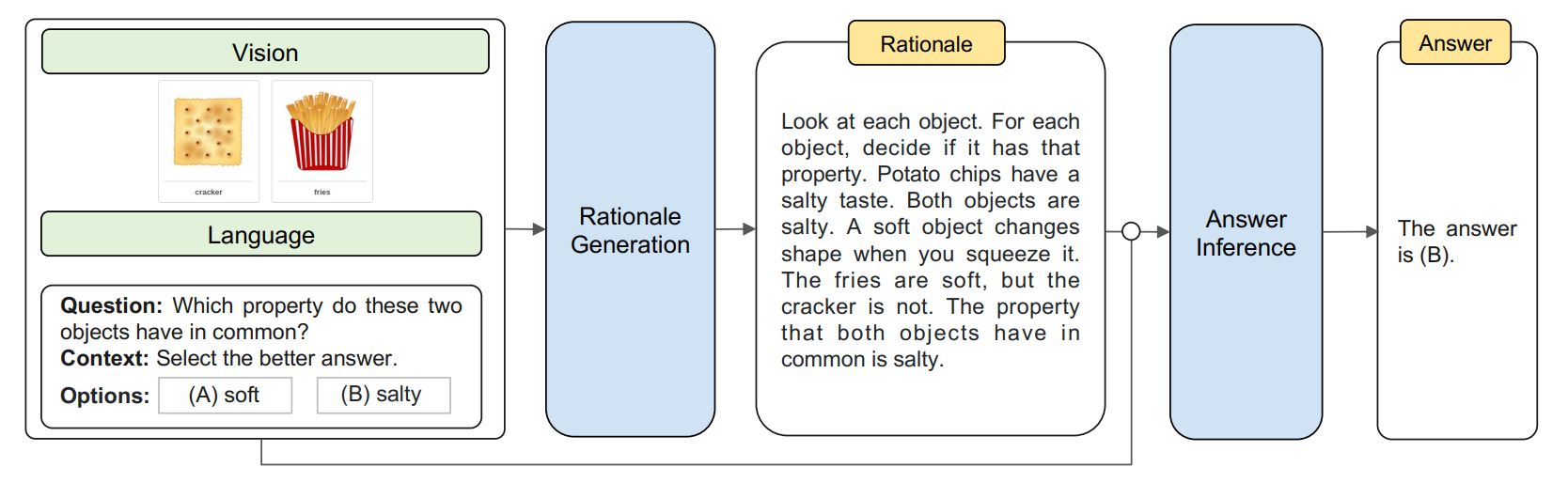
This model is awaiting public implementation releases, and is expected in the near future.
LLaMA – Meta’s answer
LLaMA stands for “Large Language Model Meta AI”. It is a highly flexible and adaptable LLM introduced by Meta. It has four versions (7B, 13B, 33B, and 65B parameters) which can be trained and deployed with smaller infrastructure, making it lightweight compared to others. The 7B model has been trained on 1 trillion tokens, while 65B model is trained on 1.4 trillion tokens.
The current release is still in its foundational stage, and requires more effort on word filtering and context awareness. It has been released for limited access. The advantage posed by LLaMA is that its training has been done exclusively on publicly available data like GitHub, Wikipedia, Gutenberg journals, ArXiv, and Stack Exchange.
LLaMA is fully open source, and even its 13B model is performing at par with the likes of GPT 3.
NVIDIA’s NeMo Megatron
NVIDIA has developed an LLM service of its own, called NVIDIA NeMo. It runs on NVIDIA’s own AI platform to customize and deploy LLM services on the cloud, packaged with API access.
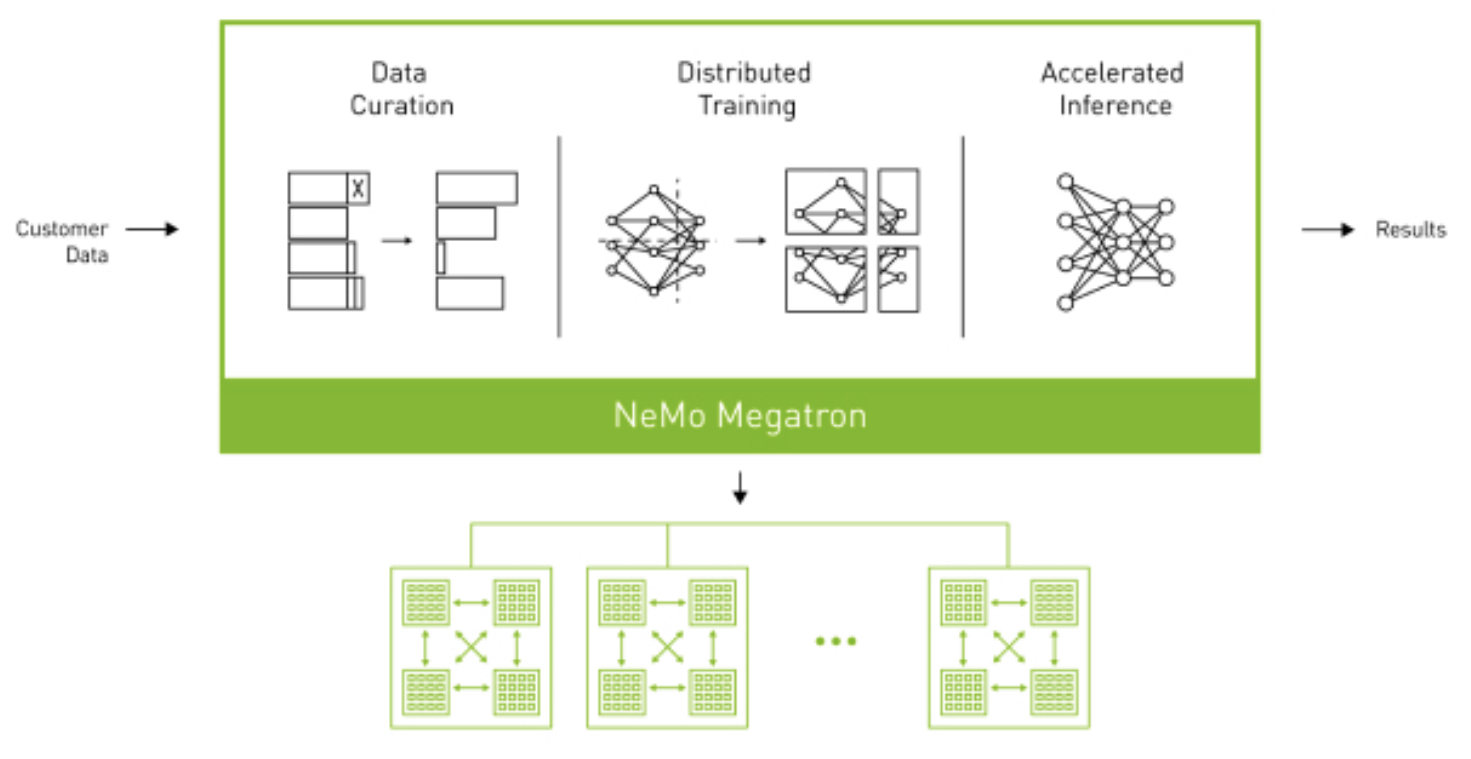
NeMo Megatron provides an end-to-end framework for training and deploying LLMs with up to trillions of parameters. It is deployed as containers with access to GPU-backed and MPI-enabled multi-node compute power provided by NVIDIA Triton Inference Server, enabling massively parallel training and tuning.
Taking the big decision
The likes of ChatGPT have created a revolution by which AI models are getting more publicly accessible, democratising the ecosystem. The impact has been so large that ChatGPT is being featured in the cover page of TIME Magazine.
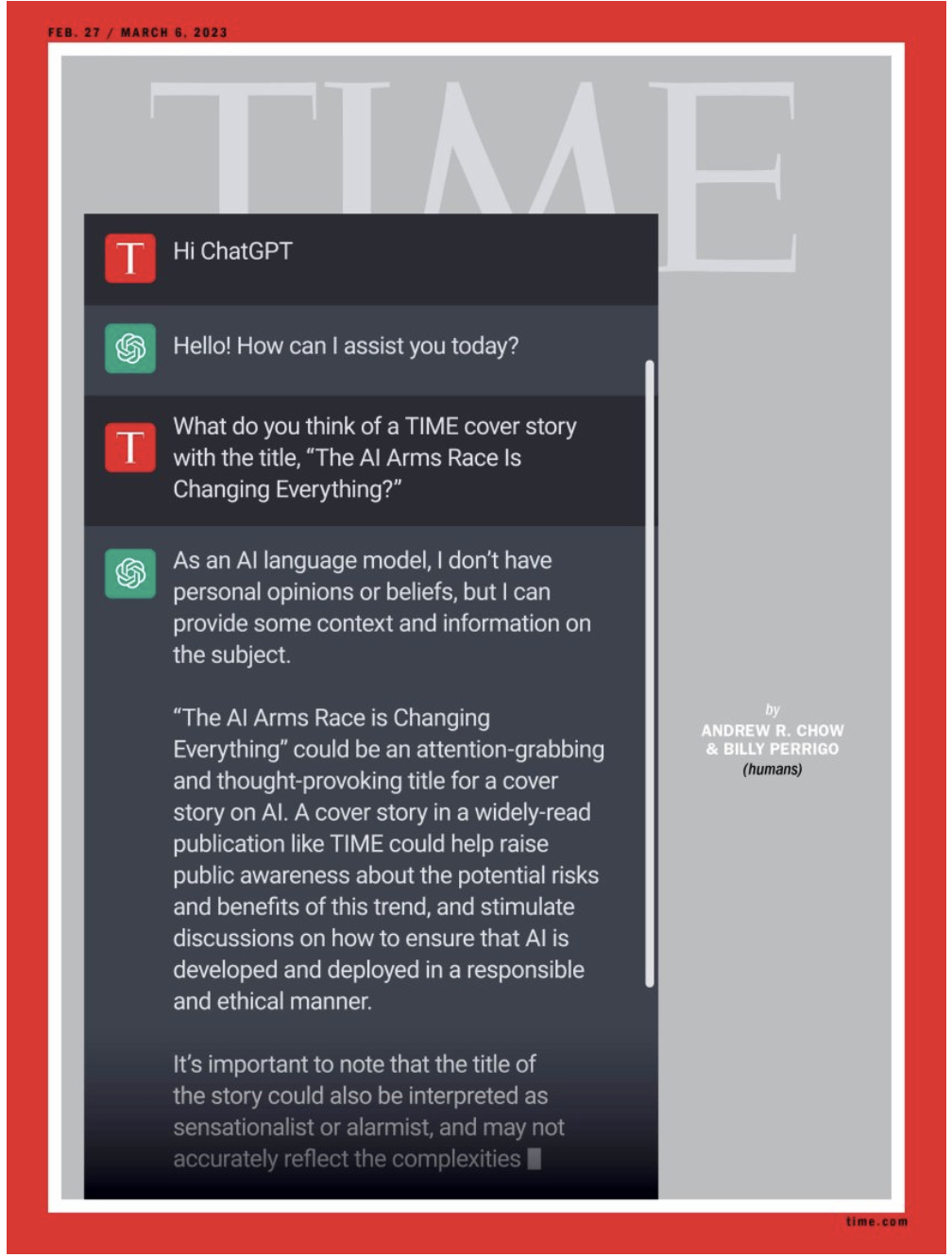
With the arrival of virtually unlimited compute and storage capabilities, these models are poised to get better with time, increasing our dependency on them. With this great power, comes great responsibility on our hands to use them ethically. While the models can potentially replace redundant tasks, they are not expected to overpower human thought in any recent timeline, primarily since they are only as good or as bad as the data we feed into them. Hence it may be good to join forces with such models rather than fighting them. Some purposes are:
- Generating code templates for coding tasks.
- Code reviews.
- Reducing ramp-up time for new technologies during training.
- A general learning tool.
- Language practice and translation.
The adaptation curve now falls on the users to identify use cases where it is worth using these tools, and making sure all of us level up our skills and requirements to make the tools worth their existence.
References
- https://www.ibm.com/in-en/topics/conversational-ai
- https://www.nvidia.com/en-us/deep-learning-ai/solutions/large-language-models/
- https://towardsdatascience.com/specialized-llms-chatgpt-lamda-galactica-codex-sparrow-and-more-ccccdd9f666f
- https://openai.com/blog/chatgpt/
- https://platform.openai.com/docs/introduction/overview
- https://huggingface.co/transformers/v3.5.1/model_doc/gpt.html
- https://blog.google/technology/ai/lamda/
- https://arxiv.org/pdf/2201.08239.pdf
- https://en.wikipedia.org/wiki/LaMDA
- https://arxiv.org/pdf/2302.00923.pdf
- https://github.com/amazon-science/mm-cot
- https://github.com/lupantech/ScienceQA/tree/main/data
- https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
- https://scontent.fcok10-2.fna.fbcdn.net/v/t39.8562-6/333078981_693988129081760_4712707815225756708_n.pdf?_nc_cat=108&ccb=1-7&_nc_sid=ad8a9d&_nc_ohc=0JlbsRuMCfYAX8OSaCn&_nc_ht=scontent.fcok10-2.fna&oh=00_AfB9VbZKhHhXcUysL2b8NXjyXl0G–EEZVOW3hUDKaGbRw&oe=63FFCFA2
- https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md