Data Lakes
A data lake is a central repository where a lot of organized and unstructured data are kept until they are needed. Each piece of data in the data lake is given a special identification and a set of metadata tags. In contrast to conventional data warehouses and databases, data lakes can manage all forms of data, including the unstructured and semi-structured data needed for machine learning use cases, such as photos, video, and audio. Because computer resources are managed individually and the data is kept on object storage, the cost of storing massive amounts of data is decreased.
Maturity levels of data lake in an organization
• Data source identification: The data lake is used in the initial step to permanently store the raw data before making it accessible to users. Raw data from various sources is kept on file. At this point, the data that will be saved should be labeled and classified using an appropriate and secure management strategy. Companies start using the data lake more actively at this point.
• Testing and learning a data lake environment: This step focuses on converting and analyzing the data that was gathered in the previous stage, which was data collection. Using unaltered data, experiments are carried out to determine the best tool for the business.
• Integrate data lakes to current data warehouses : Businesses combine data lakes and data warehouses for data analytics.
• Data lake as a service: At this point, the data lake functions as both a source of data for the business and a key component of the organization’s data infrastructure.
Data Lakes vs Data Warehouse
In order to store huge data, two main methods exist: data lakes and data warehouses. Both are essentially storage repositories that incorporate different data stores. Yet there are some significant differences between the two strategies:
• The data that is stored in a data warehouse follows a specified structure. A data lake, however, lacks a fixed schema.
• Data warehouses only process and store structured data, but data lakes process and store all sorts of data, including structured, semi-structured, and unstructured (raw) data.
• When it comes to massive data, data warehouses are often more expensive than data lakes. It offers speedier query results and better performance, nevertheless.
•Business analysts are the usual consumers of data warehouses, whereas data scientists, business analysts, and data developers are the typical users of data lakes.
Data Lake Architecture
The architecture of a data lake cannot be characterized by a single formula. Three key data lake architectural ideas do exist, which are as follows:
1. All data, whether structured or unstructured, is fed into the data lake.
2. The data is kept in an incompletely transformed or unconverted state in the data lake.
3. The data is transformed and inserted into a schema in line with the business need.

• Ingestion Layer: The data lake levels’ initial layer is the ingestion layer. It collects information and adds unprocessed data from multiple sources to the data lake. Raw data is prioritized and categorized by the ingestion layer.
• Distillation Layer: This layer takes the ingestion step’s data and transforms it into structured data for simpler and more effective analysis. In this stage, data preparation gets started. The distillation layer cleans and changes the intake layer’s raw data for effective analysis.
• Processing Layer: The processing layer executes interactive, real-time, and batch user queries as well as analytical tools on structured data.
• Insights Layer: The query interface is represented by the insight layer. Data analysis can make use of SQL or NoSQL queries.
• Unified Operations Layer: This layer is in charge of overseeing system administration and monitoring. Both data management and workflow management are done by it.
Advantages of Data Lakes
A data lake provides unparalleled scale and a great degree of flexibility to handle data using many technologies, tools, and computer languages. Businesses may lower direct infrastructure costs despite holding significant amounts of data and lower the cost of semi-structured data input into a warehouse by separating storage and computing.
There are several benefits to a data lake strategy in the circumstances we have described:
• Resource optimization: When operating at large sizes, data lakes may be significantly less expensive than databases by separating (cheap) storage from (expensive) computational resources.
• Reduced ongoing maintenance: As data is ingested without being transformed or structured in any way, adding new sources or changing current ones is simple and doesn’t need the creation of special pipelines.
• Wider range of use cases: Since you are not constrained by the way you decided to format your data upon its input, data lakes provide companies greater freedom in how they ultimately choose to deal with the data. As a result, they may support a wider range of use cases.
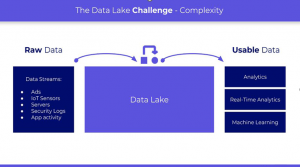
Data Lake Challenges
The management of data lakes is notoriously challenging. They may also be quite expensive when considering the total cost of ownership (which includes engineering expenditures), and data lake initiatives can take years to begin providing substantial benefits. Moreover, data security and governance must be established independently.
Despite various benefits, it is a sad fact that the majority of big data initiatives fail. Typical challenges include:
• Technical complexity: Most data lake architectures require a team of dedicated data engineers to maintain the plethora of building blocks, pipelines, and moving parts that make up a data lake architecture. Not only are most data lakes not self-service for business users, but they are also not self-service even for experienced developers.
• Slow time-to-value: Data lake initiatives can take months or even years to complete, draining resources that are become harder to justify.
• Data swamps: While storing raw data gives you a lot of freedom, ignoring data governance and management principles can cause businesses to stockpile a lot of data that they won’t likely ever use and make it harder to retrieve the data that might be valuable.
• Security and compliance: Due to limited data visibility and the inability to natively alter or remove information, implementing access control, security, and governance in a data lake is challenging. When records must be deleted for compliance reasons, this can be a pain.