
Data Lake, A new ideology in Big Data Era
What is Data Lake ?
Data Lake is a central storage repository which holds a huge amount of data or big data in raw unprocessed format. Data can be stored in a more flexible format as it supports structured, semi-structured and unstructured data. In a data warehouse, data is stored in hierarchical manner and as tables but in a data lake, data is stored in a more organized and easy to use way like an apartment architecture, usually in files or in an object store. Data lake also provides a vast amount of data to increase analytical accuracy.
As the name indicates ,data lake is similar to a real lake with multiple tributaries flowing into it. Data Lake configurations are done on a cluster of low cost and scalable commodity hardware so that any amount of data can be loaded into the lake and used whenever it is needed without thinking about storage. So it is definitely a cost-effective way to store all of an organization’s data for later use, and the data cluster can be on-premise or in the cloud.
Why Data Lake?
It is not necessary to define the schema in advance when we use Data Lake. Hence, we can handle various types of data in various formats. As a progress of this data lakes are an important architectural component in many organizations now a days.
Organizations use Data Lakes as a platform for Big Data analytics and other data science applications that require a large sum of data and activities with advanced analytics techniques which includes data mining, predictive analytics, machine learning, and so on.
- Storage of information became easy with the use of storage engines like Hadoop .
- It is no longer needed to model data in an enterprise-wide schema.
- Increased analytical quality with the increase in data volume, quality, and metadata.
- Business agility is one of the benefits of Data Lake
- Machine learning and artificial intelligence helps in making profitable predictions .
- competitive advantage for the implementing organization.
- Data Lake gives a complete view of customers and makes analytics more powerful.
Data Lake Architecture
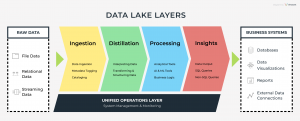
Data lake conceptual model
Ingestion Layer
Ingestion Layer is used for consuming raw data into the Data Lake .Raw data can’t be altered .Raw data can be ingested in batches or in real-time, and is organized in a folder structure.The Ingestion layer can contain data from different external sources, such as:
- Social networks
- IoT devices
- Wearable devices
- Data streaming devices
Ingestion layer quickly ingest almost any type of data that any system covers :
- Real-time data from connected health monitoring devices
- Video streams from security cameras
- Videos, photos or geolocation data from cell phones
- All types of telemetry data
Distillation Layer
The Distillation Layer transforms the data stored from the Ingestion Layer to structured data for further analysis. In this layer raw data is refined and transformed into structured data sets and subsequently stored as files or tables. In this stage data is cleansed, denormalized, andderived , and then becomes uniform in terms of encoding, format, and data type.
Processing Layer
In the processing layer ,structured data is being executed by user queries and advanced tools which are available for data analysis. Data can be executed in real-time, batch, or interactive methods. With the help of analytical applications, business logic is applied and data is processed. The processing layer is also known to as “trusted”, “gold” or “production ready”.
Insights Layer
This layer is the query interface .The Insights layer uses SQL and non-SQL queries as input and output data that is available in reports or dashboards.
Unified Operations Layer
This layer performs system monitoring and manages the system using workflow management, auditing, and proficiency management.
The Sandbox layer will also be a part of Data Lake implementations.This layer is a place for data exploration for Data scientists and advanced analysts as the name indicates . The sandbox layer is also called the exploration layer or data science layer.
Pros and Cons of using Data Lake
Pros of using Data Lake :
- Fully assists with Production related setup and advanced analytics.
- Provides scalability and flexibility at low cost.
- Values are provided from unlimited types of data.
- Reduces long-term operational costs.
- Enables economical storage of files.
- Quickly adapts to changes .
- Centralizes multi-content sources .
- Easy access to data.
Cons of using Data Lake:
- Data Lake may lose its relevance and momentum eventually.
- Data lake development is perilous.
- Raw data can lead to unexpected issues, irrelevant data, disparate and complex tools, enterprise-wide collaboration, uniformity, consistency and commonality.
- Increase in cost of storage and data processing.
- Unavailability of information from others who have worked with the data because there is no record of the history of previous analysts’ findings.
- Risk with security and access control. Sometimes data can be placed in a lake without foreseeing future issues, as some of the data is subject to privacy and regulatory requirements.