
AWS Glue
What is AWS Glue?
Amazon Glue consists of three components: the AWS Glue Data Catalog, an ETL engine that automatically creates Python or Scala code, and a configurable scheduler that manages dependency resolution, task monitoring, and restarts. The Glue Data Catalog enables users to quickly find and retrieve data. Customization, orchestration, and monitoring of complicated data streams is also possible through the Glue service.
Features of AWS Glue
Amazon Glue provides all the features you need for data integration, so you can gain insights in minutes instead of months and leverage your knowledge for new developments.
Drag-and-drop interface: a drag-and-drop job editor lets you create the ETL process, and AWS Glue instantly builds the code to extract, convert, and upload the data.
Automatic schema discovery: you can use the Glue service to create crawlers that connect different data sources. It organizes the data, extracts schema-related information, and stores it efficiently in the data catalog. This data can then be used by ETL tasks to monitor ETL processes.
Job scheduling: Glue can be used on a schedule, on demand, or in response to an event.
Code generation: without having to write custom code, Glue Elastic Views lets you easily create materialized views that aggregate and replicate data across different data stores.
Built-in machine learning: Glue has a built- in machine learning feature called “FindMatches”. It detects data sets that are incomplete copies of each other and deduplicates them.
Developer Endpoints: Glue provides developer endpoints that allow you to modify, debug, and test the code you create when you want to actively build your ETL code.
Glue DataBrew: It is a data preparation tool for users such as data analysts and data scientists that helps them clean and normalize data using Glue DataBrew’s active and visual interface.
AWS Glue Architecture
In AWS Glue, you define jobs to perform the process of rooting , converting, and lading( ETL) data from a data source into a data target. The following are the way that you need to perform
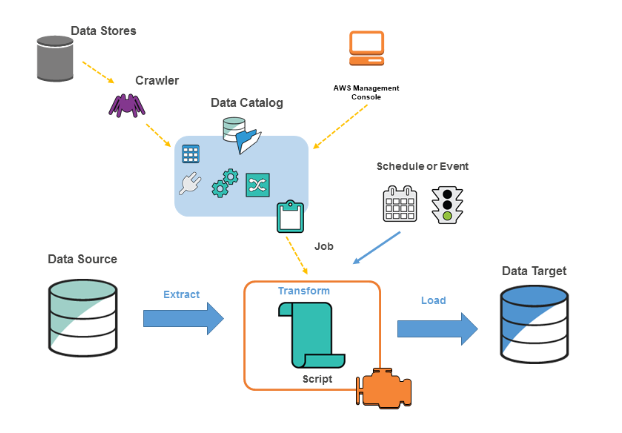
- First, you need to decide which data reference you’re using.
- You need to produce a straggler to feed the AWS Glue Data roster with metadata table delineations, If you’re using a data store source.
- When you target your straggler to a data store, the straggler populates the data roster with metadata.
- you need to explicitly produce Data register tables and data stream characteristics, If you’re using streaming sources.
- Once the data roster is distributed, the data is incontinently searchable, queryable, and available for ETL.
- AWS Glue converts the data by creating a script. You can also use the Glue press or API to emplace the script.( In AWS Glue, the script is run in an Apache Spark terrain)
- After you produce the script, you can run the task on demand or schedule it to start on a specific event. You can use a time- grounded schedule or an event as the detector.
- As you run the job, the script excerpts the data from the data source, transforms it, and loads it into the data target, as shown in the figure over. In this way, the ETL( excerpt, transfigure, cargo) job is successful in AWS Glue.
AWS Glue Data Catalog
There is one Amazon Glue Data Catalog per AWS location in each AWS account.Each data catalog is a largely scalable collection of tables organized into databases. A table is a metadata representation of a collection of structured or semi-structured data stored in sources similar as Amazon RDS, Apache Hadoop Distributed range System, Amazon OpenSearch Service, and others. The AWS Glue Data Catalog provides a unified depository where distant systems can store and find metadata to keep track of data in data silos. You can also use the metadata to query and convert that data in a nonconflicting way across a variety of operations.
Below are other AWS services and open source systems that use the AWS Glue Data Catalog
- Amazon Athena
- Amazon Redshift Spectrum
- Amazon EMR
- AWS Glue Data Catalog customer for the Apache Hive metastore
Amazon Glue’s Benefits and Drawbacks
Here are some of the advantages of Amazon Glue:
- Glue is a serverless data integration tool that removes the need for infrastructure creation and management.
- It offers easy tools for creating and tracking job tasks that are prompted by schedules, events, or on-demand.
- It is a low-cost option. You only need to pay for the resources you use during the task execution procedure.
- Glue will create ETL pipeline code in Scala or Python based on your data sources and targets.
- Multiple organizations within the business may use AWS Glue to cooperate on different data integration initiatives. This reduces the quantity of time required to analyze the info.
Limitations
- Glue has integration constraints. Only ETL from JDBC and S3 (CSV) data sources functions correctly with Glue. If you want to import data from other online services, such as File Storage Base, Glue cannot help.
- Glue is not used to manage individual table tasks. The ETL method is only used to handle the entire database.
- Amazon Glue only supports a few data sources, such as S3. As a consequence, there is no way to integrate continuously with the data source. This implies that real-time data for complex operations will be unavailable.
- For changing ETL scripts, Amazon Glue only supports two computer languages: Python and Scala.
Conclusion
AWS Glue is a serverless, low-cost service that provides easy-to-use tools to catalog, cleanse, enrich, validate and move your data for storage in data warehouses and data lakes. AWS Glue can work effectively with semi-structured and stream data. It is compatible with other Amazon services, can combine data from multiple sources, provides centralized storage, and prepares your data for the next phase of data analysis and reporting.