
Object Detection with Edge Computing
Object detection is a popular Computer Vision and Artificial Intelligence technique which finds a wide range of applications from agriculture to the futuristic world of automated cars. All of you might be daily users of object detection in some form or another, whether it is Google Lens or face detection in mobile phones.

In this blog, we will analyze object detection, especially, detection with edge devices, and check whether edge device is a feasible option for object detection.
A glimpse of Object Detection
Fundamentally, object detection is about locating and identifying the instances of objects in images or videos.
In simple words, object detection = Localization + Classification.

Modern high performance object detection models are typically powered by Machine Learning or Deep Learning (quite unsurprising, right?) to produce meaningful results.
Edge Computing
Edge computing is a distributed computing paradigm. Philosophy of edge computing is to bring computation and data storage maximum closer to the sources of data. Even though edge computing is popularly compared and contrasted with cloud computing, edge computing is not about avoiding cloud resources completely. Instead, edge computing allows data from IOT devices to be analyzed at the edge of the network before being sent to the cloud. Here, we don’t need to send important chunks of data through the internet and hence we don’t need to wait for responses from the cloud or data center. This in turn helps to improve response times and save bandwidth.
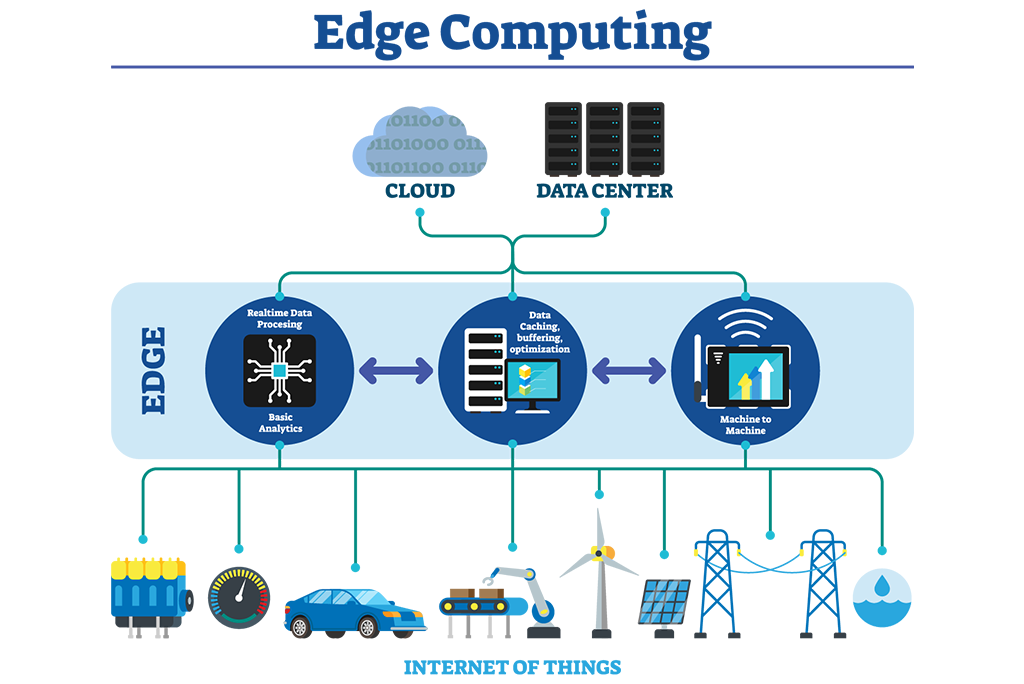
Why Edge Computing
Advantage of edge computing over typical cloud computing is the access to the data from close distance. This will be very much critical when the system reliability should not be compromisable.
You can’t defeat the speed of light. Next gen experiences will require us to completely rethink the current internet. Data proximity and data velocity will be embedded in the urban core.
Cole Crawford, Vapor I O
Let us consider the case of automated cars. If we rely completely on cloud storage for input data analysis and detection, then the car will go out of our control when it loses internet access. All of this can happen within seconds. Instead, if we rely on edge devices for important processes then even if we lose internet access for some more time, the vehicle will be in the system’s control.
These are some of the advantages of edge computing over typical cloud computing:
- Privacy and security
- Reliability
- Speed
– brings analytical computational resources close to the end users.
– increase the responsiveness and throughput of applications. - Ensure “always on” availability.
- Efficiency
– Avoiding transmission over the internet.
– significant bandwidth savings.
Challenges
In order to create a well performing object detection algorithm, we need to overcome many challenges.
Smooth seas do not make skillful sailors.
African proverb
Inherent challenges in object detection:
- Real-time images can be of low quality.
- blurring, motion blur, noises, etc…
- Objects can be one-to-many and many-to-one. That is different objects can look similar and objects of same category can look different.

Challenges in computer vision with edge devices:
- Limited memory availability.
- Model Quantization is essential to export model to the edge device. Quantization may reduce the model performance since it drastically reduces model size.
Algorithm
In this section, we will see how to build and deploy an Object detection model for edge devices.
Steps to follow:
- Data collection
- Data preprocessing and Data augmentation
- TensorFlow lite model creation via transfer learning.
- Evaluating the model
- Finetune the model based on the evaluation metrics obtained during testing.
- Quantize and export the model
- Deploy the exported model in the edge device for real-life on-site implementation.
Dataset Creation
In order to train the model, we need a good dataset as input. For object detection algorithms, there are two types of dataset files required for training. i. e, images and annotation files.
Initially, you have to collect images with all of our target objects. Then, annotate labels for these images using any of the annotation tools.
Data Preprocessing
There are some preprocessing steps that we need to do in order to make the images suitable for the model to train. Image preprocessing steps like image augmentations help to improve the model precision. Another preprocessing steps include image rescaling, train-test split etc… Image rescaling is used to fit the model for the input tensor shape of the model.
Augmentation
Image augmentation is a technique of altering the existing data to create some more data for the model training process. In other words, it is the process of artificially expanding the available dataset for training a deep learning model.

To make a training dataset, you need to obtain images and then label them. For example, you need to assign correct class labels if you have an image classification task. For an object detection task, you need to draw bounding boxes around objects. This process requires manual labor, and sometimes it could be very costly to label the training data.
Since, all of these images are generated from training data itself we don’t have to collect them manually. This increases the size of the training sample without going out and collecting this data. Note that, the label for all the images will be the same and that is of the original image which is used to generate them.
Model Training using Transfer Learning
It is a Herculean task to design and build an object detection model from scratch. We need a lot of dataset, computational power, effort and time to build such model. To avoid these challenges, we can use pre trained models from world class research groups in universities, corporations etc.
In the long history of humankind, those who learned to collaborate and improvise most effectively have prevailed.
Charles Darwin
(1809 – 1882, English naturalist)
Transfer learning is about sharing the knowledge or reusing an already-trained model. Model trained on one task is re-purposed on a second related task. State-of-the-art pretrained Object detection models are available in online sites like TensorFlow hub. We can download and retrain these sophisticated models and can be used for our specialized applications.
We should choose our model according to our application, requirements etc… For example, models like YOLO-Lite and EfficientDet-Lite are popular models for object detection in edge device.
Model Evaluation
Evaluating a model is a core part of building an effective machine learning model. The model development happens as a constructive feedback principle. Build a model, get feedback from metrics, make improvements and continue until we achieve a desirable accuracy. Evaluation metrics explain the performance of a model. Different evaluation metrics are used for different kinds of problems. For object detection algorithms, we typically use Mean Average Precision (mAP).
To evaluate the detection commonly we use precision-recall curve curve but average precision gives the numerical values so it is easy to compare the performance with other models. Based on the precision-recall curve AP it summarizes the weighted mean of precisions for each threshold with the increase in recall. Average precision is calculated for each object. Mean average precision is an extension of Average precision. In Average precision, we only calculate individual objects. But in mAP, it gives the precision for the entire model.
In multi-class detection, where every bounding box regressed can contain one of the available classes, the standard metric used to evaluate the performance of the object detector is the Mean Average Precision (mAP). Computing it is straightforward—the mAP is the average precision for each class in the dataset.
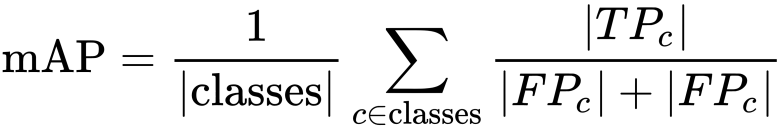
Fine Tuning
Continuous improvement is better than delayed perfection.
Mark Twain
We should fine tune the hyper-parameters for a better and specialized model. We can tune the parameters according to our dataset requirements like object size, shape etc. So, we can specialize the model for the given dataset and requirements using hyper-parameters.
Quantization
As we said earlier, memory is a valuable and limited resource in edge devices, since edge devices are very compact. Hence we use a compression technique called as Quantization. It enables high-performance deep learning computation on small devices. But if done improperly, weight quantization will cause severe performance degradation, since compression can result in information loss.
To avoid performance deterioration due to quantization, follow quantization aware training. i. e, for object detection in edge detection, instead of doing typical model training, anticipate the chance of quantization and train the model accordingly. We can do specialized quantization techniques like full-integer quantization according to our memory availability. In addition, we can apply segmentation of the model if we need to parallelize the model for multiple edge TPUs, so that model speed can be scaled.
Deployment on Edge Device
You have to select the optimum device for your application by considering factors like memory size, cost, edge TPU specifications, power requirements etc.
These are the steps to be done for the edge deployment of the model:
- Set up the edge device.
- Download our quantized lite model .
- Invoke our quantized model to the inference code.
- Run Detection for your new input image.
Conclusion
As we saw above, object detection in edge devices is a very useful and reliable technology. While preparing a model for object detection, you should check the possibility of edge computing if you require an “always on” and uninterruptible system.
Whereas, edge devices have a very limited memory storage and data processing capability. It is suggested to use cloud services along with edge devices, if your system needs a lot of memory for data storage and additional processing. So that we can use edge devices for emergency processes and cloud storage for less urgent purposes.
References
- Object Detection With Deep Learning: A Review. (2022). Retrieved 18 March 2022, from https://ieeexplore.ieee.org/abstract/document/8627998
- Khan, W., Ahmed, E., Hakak, S., Yaqoob, I., & Ahmed, A. (2022). Edge computing: A survey. Retrieved 18 March 2022, from sciencedirect.com/science/article/abs/pii/S0167739X18319903
- GitHub – tzutalin/labelImg (2022). Retrieved 18 March 2022, from https://github.com/tzutalin/labelImg
- Wu, H., Judd, P., Zhang, X., Isaev, M., & Micikevicius, P. (2022). Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation. Retrieved 18 March 2022, from https://arxiv.org/abs/2004.09602
- YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. (2022). Retrieved 18 March 2022, from https://ieeexplore.ieee.org/abstract/document/8621865