
Text Mining- Introduction
In todays world ,the amount of the data that we produce every day are really very high. Through the evolution of communication via social media, we generate Tons and Tons of Data. But in this whole set of generated data , only small percentage of data is in the structured format and the rest is the unstructured data like the text messages ,comments and Likes in the social Media and also the large set of emails that are sent out everyday. Data is the key to many Businesses ,If analyzed the data correctly and found the hidden patterns of it and extracted the valuable information of it, then the Business can be grown successfully. So if this kind of data can be analyzed /mined and brought more value to the data, then its going to be useful to the business for their future run. So here comes the importance of Text Mining.
Text mining, also known as text analysis, is the process of transforming unstructured text data into meaningful and actionable information. It is the process of deriving meaningful information from the Natural Language Text.
For text analysis, it uses natural language processing(NLP) to extract meaningful information from the unstructured text in a document. It is done by the process of classifying texts by sentiment, topic, and intent.
NLP(Natural Language Processing) is a part of computer science and artificial intelligence which deals with Human languages which can be in spoken/written format. With the help of machine learning, the models which are trained with this data are able to predict with a certain level of accuracy automatically.
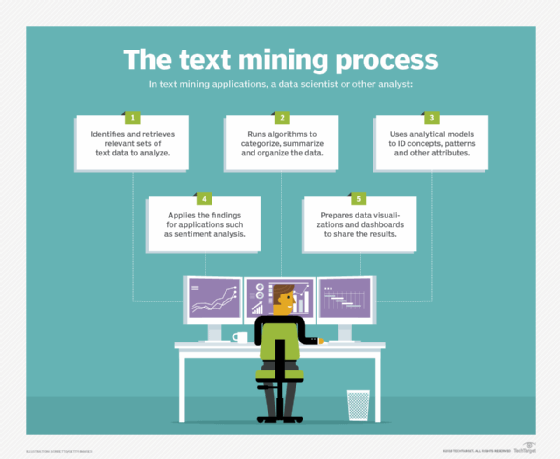
Text Mining, Text Analysis, and Text Analytics
Text mining and text analysis are similar words. Text analytics is different.
Text mining provides qualitative results by identifying the valuable information with a text. Text analytics provides quantitative results by finding patterns and trends across large sets of data. Text analytics is used to create graphs, tables and other kinds of visual reports.
Techniques Used in Text Mining:-
1.Information Extraction
2.Categorization
3.Clustering
4.Visualization
5.Summarization.
Information Extraction is a technique which analyzes the unstructured Text in a document . This is done by identifying the relevant important words and its relationship between them. The order of text can be identified by the pattern matching technique. This technique involve language processing with the help of NLP which automatically process and analyze the unstructured text data using methods like tokenization, parsing, lemmatization, stemming and stop word removal . It is used when there is an outsized amount of data.
Categorization technique arranges the text document in one or more category. It is also known as Text Classification or Text Tagging. This process includes pre processing, indexing, dimensional reduction and classification. The text can be categorized using techniques like Decision tree, Nearest Neighbor classifier . Examples are SMS categorization , spam filtering and hierarchical categorization of web pages.
Clustering is done to group text documents which has similar contents. It has partitions called clusters and each partition will have documents with similar contents. Clustering makes sure that no document are omitted from the search and it derives all the documents which has similar contents. It compares each cluster and determines how the document are connected to each cluster.
Visualization technique is done in order to simplify the process of finding relevant information. This is a graphical representation that contains the information and the data. It uses text flags to represent documents or group of documents and uses colors to point the compactness. Visualization technique helps to visualize textual information in a more attractive way. Examples are graph, chart, word cloud, map, network, timeline.
Summarization technique will generates summaries for large text documents. This will help to reduce the length of the document and summarize the details of the documents in brief easily and quickly while maintaining key points and overall meaning . It helps to understand the content at a glance. This technique is very fast. It is used in search engines to allow a user to assess the relevance of returned results.
Methods and Models Used in Text Mining:-
Based on the information retrieval Text Mining has four main methods:-
1.Term Based Method (TBM)
2.Phrase Based Method (PBM)
3.Concept Based Method (CBM)
4.Pattern Taxonomy Method (PTM).
Term Based Method :- The ‘term’ in document means the word with semantic meaning. Here the whole set of documents is analyzed on term basis. The disadvantage of this method is the problem of synonymy and polysemy. Synonymy is where multiple words having the identical meaning. Polysemy is where one word has more meanings.
Phrase-Based Method :- In this method, the document is analyzed based on the phrases which are less obvious to more meanings and more discriminative. The disadvantages of this method include
They have lower statistical properties to terms.
They have a small frequency of occurrence.
They have a large number of noisy or terminated and piercing phrases.
Concept-Based Method :- here, the document is analyzed based on the sentence and document level. Text Mining methods are based on overall analysis of term. This statistical analysis of the term frequency captures the significance of the word without document. In this method 2 terms can have same frequency in same document. But here the significance is that one term gives more accurately than the significance given by the other term. The terms that acquires the semantics of the text must be given more significance.
There are three main components in this method.
1-it examines the meaningful part of the sentences.
2-produces a conceptual ontological graph to explain the structures.
3-can understand and mark important and unimportant words.
Pattern Taxonomy Method:- Here, the document is analyzed on the patterns. Patterns in a document can be identified using data mining techniques ( association rule mining etc).
This is a successful technique which overcomes the low frequency and misinterpretation problems in text mining. The two processes used in this method are pattern deploying and pattern evolving. This method is best compared to all the other models or methods.
How does Text Mining work:-
Text Classification
Text Extraction
Text Classification
This process helps in setting categories or tags to the unstructured data with NLP which structures and organizes the complex text, into meaningful data.
So by analyzing the information from the massive set of emails or support tickets (unstructured text data),we can obtain valuable / meaningful insights in a fast and successful way.
Popular tasks /processes for text classification are – topic analysis, sentiment analysis, language detection, and intent detection.
Topic Analysis: helps you to understand the main subjects or topic of a text and organizes text data. eg:- a ticket saying “I didn’t receive the order”, is classified as Shipping Issues.
Sentiment Analysis: This analyzes the emotions that contains in a given text .Also understands the opinion and feelings in a text, and mark them as positive, negative, or neutral.
Language Detection: This classifies or tags a text based on its language.
Intent Detection: With the help of text classifier this process helps to recognize the intentions or the purpose behind a text .This is very useful when analyzing customer conversations.
Text Extraction
Text extraction is also called as Keyword Extraction .It is a technique that extracts specific or relevant information from a text, like keywords, addresses, emails, entity names etc.
Main methods of text extraction include keyword extraction, named entity recognition, and feature extraction.
Keyword Extraction: It is the process of extracting important keywords/phrases from the text data because keywords are the most important terms within a text which can summarize the whole text. By a keyword extractor we could index the data or keyword to be searched, summarize the content , also we can create tag clouds.
Named Entity Recognition: It is also called as entity extraction or chunking. It allows to identify and extract the critical information from the text data. This can be the names of companies, organizations, or persons which are in a text data.
Feature Extraction: This helps to spot the critical features or specific characteristics of an entity or a product in a text data. Also it helps in understanding the descriptions of a product and simply extract features like its brand and model, colour etc.
Benefits of Text mining
Text Mining helps to make Data driven decisions and makes the companies more productive by gaining better insight into the customer sentiment and customer reviews. Customer service , Fraud detection, online advertising, Healthcare, Risk management, and website content management are other examples that can gain from the use of text mining tools.
Text mining or text analytics is a booming technology .This has made big impacts on many industries and is still extending its services to the others. The results and analysis may vary from business to business. In order to gain knowledge about content-specific values, text mining is a good option for the organizations.