
The mindset to design a NoSQL Database.
After adopting NoSQL by the industry and the increasing NoSQL database options, it has become a trend in considering NoSQL as an alternative to relational Databases for software development. With the increasing technologies, traditional ways of storing data are being challenged.
Relational database modeling is typically driven by the structure of available data. The main theme of the design is “What answers do I have?”
Data modeling of NoSQL is typically driven by application-specific access patterns, i.e. the types of queries to be supported. The main theme of the design is “What questions do I have?”
Relational Databases have been there for several decades and is not difficult to find developers who have the knowledge and experience in writing SQL queries, designing entity relationships, normalizing schemas and ensuring ACID properties. This is not the case with NoSQL where knowledge, expertise, and experience are scarce. Those developers coming from a Relational Database background tend to designs the NoSQL database by adopting the fundamentals of Relational Databases.
SQL vs NoSQL
The argument that lies between SQL vs NoSQL is nothing but the comparison of relational vs. non-relational databases. The difference lies in how they’re built, the kind of information they store, and the way they store it. Relational databases are very structured, while non-relational databases are document-oriented and distributed. For many years now, the Structured Query Language (SQL) databases have been a primary data storage mechanism. With the growing trend of web applications and open-source options like PostgreSQL, MySQL, and SQLite. NoSQL databases have been recently gaining popularity with options such as MongoDB, CouchDB, Redis, etc… End of the day, both SQL and NoSQL do the same thing, i.e to store data except that their approaches differ. Always remember NoSQL is not a replacement for SQL, it’s an alternative. Some projects are better suited to using a SQL database, while others work well with NoSQL. Some could use both interchangeably.
Few Drawbacks in SQL.
However there are certain drawbacks to SQL and in a few circumstances, these drawbacks become such a problem that we are willing to sacrifice the flexibility it provides to overcome them.
- It does not scale well horizontally. Trying to split your data across many smaller machines is not impossible, can have a huge impact on performance. Large SQL databases tend to run on high power very expensive hardware to try and maintain its performance, whereas NoSQL databases tend to easily and cheaply scale to any size by simply adding in extra commodity hardware to a cluster.
- SQL is not fault-tolerant. It’s possible to replicate your data on a second backup machine, but then you double your costs for high power specialized hardware and that hardware needs to be even more powerful to handle the extra load of keeping themselves synchronized. Compare that for example to a DynamoDb cluster, and you could be running a dozen smaller machines with data replication, even spread across multiple data centers if you wish. The load is automatically distributed, updates are pushed out across the cluster and the loss of any one machine will not be noticed by the end-user.
These two are the real reasons you should choose between the two technologies. If your database is small enough to fit on a single machine and occasional downtime while you restore from a backup is not an issue, use SQL, it will massively simplify your development and have the flexibility to adapt if your needs change. If your dataset is going to be huge, go for NoSQL.
The dilemma between NoSQL and SQL.
In short, using NoSQL databases is not difficult, using it in the right place is the challenge. First of all, it is very important to understand that NoSQL doesn’t follow the same principles as Relational Databases such as fixed schemas, normalization, support for expressive queries like SQL. One common mistake developers do is trying to normalize the NoSQL database where they screw up the entire database design, making it difficult to retrieve items efficiently.
NoSQL databases drastically differ from its other counterparts depending on the type of NoSQL database (Document Database, Key-Value Database, Graph Database, etc..) and the vendor-specific implementation (MongoDB, DynamoDB, Cassandra, etc..). Because of this, there are no universal best practices or principles for designing a database schema or for queries that fit all types of NoSQL databases. This creates the challenge in designing the unique to the respective NoSQL database type.
If we consider as an example a document database, we need to consider collection size limits, how are they partitioned, available query types, and indexing support so that it is possible to efficiently retrieve items required by the application. It is not an easy task since there are several places where things could go wrong.
NoSQL Data Modeling
In relational design, the focus and effort are around describing the entity and its relation with other entities, the queries and indexes are designed later. With a relational database, you normalize your schema, which eliminates redundant data and makes storage efficient. Then queries with joins bring the data back together again. However joins cause bottlenecks on reading, with data distributed across a cluster, this model does not scale horizontally. And this was where a new evolution of data models began:
The following figure depicts the imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full-Text Search Engines, and Graph databases:
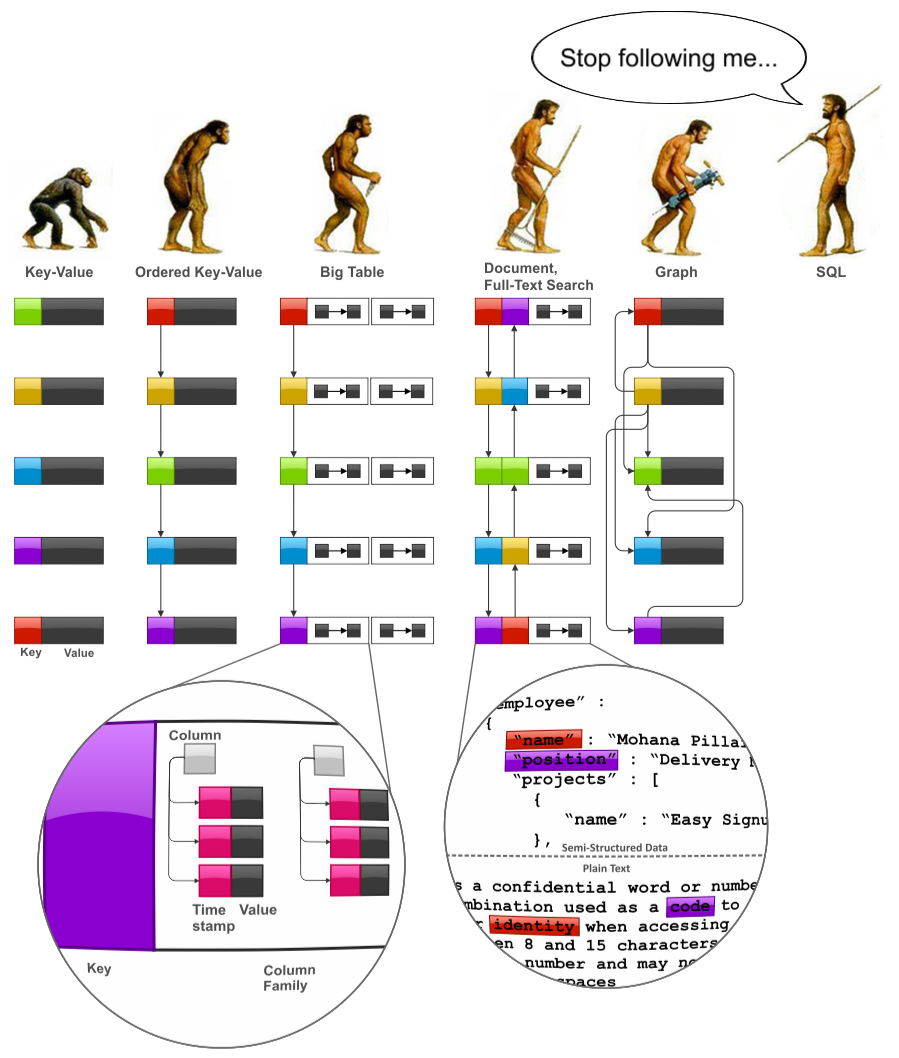
- Key-Value storage is a very simplistic, but very powerful model. One of the most significant shortcomings of the Key-Value model is poor applicability to cases that require the processing of key ranges. Ordered Key-Value model overcomes this limitation and significantly improves aggregation capabilities.
- Ordered Key-Value model is very powerful, but it does not provide any framework for value modeling. In general, value modeling can be done by an application, but BigTable-style databases go further and model values as a map-of-maps-of-maps, namely, column families, columns, and timestamped versions.
- Document databases advance the BigTable model offering two significant improvements. The first one values with schemes of arbitrary complexity, not just a map-of-maps. The second one is database-managed indexes. Full-Text Search Engines, they also offer flexible schema and automatic indexes. The main difference is that Document database group indexes by field names, as opposed to Search Engines that group indexes by field values.
- Finally, Graph data models can be considered as a side branch of evolution that origins from the Ordered Key-Value models. Graph databases are related to Document databases because many implementations allow one model value as a map or document.
Some of the best practices with Relational Databases such as not storing everything in the database still applies for NoSQL. Although it’s possible to store files such as images, transcoded videos, etc. in certain NoSQL databases, it makes more sense in storing them in a distributed file system and then uses the database to store the file metadata.
Duplicating Data in NoSQL.
If you are having a mindset of no duplication of data at the database level, it would be better to reconsider with NoSQL. Considering different types of NoSQL databases, having data attributes duplicated across different tables or collections could become even a best practice to avoid complex queries.
For instance, now storage is not that expensive, whereas processing power is more expensive in contrast. Rather than performing computationally heavy queries storing data we could store data in different forms and utilize it for direct retrieval.
You might wonder, why all these expensive queries in Relational Databases, rather storing the data and its relations with duplication in NoSQL where we could perform direct lookup and retrieval? The answer is that creating or updating data in NoSQL could become more complex when data is scattered across many tables or collections. Therefore, it is very important to evaluate the way data is being consumed and updated by the application and design the database accordingly.
Querying NoSQL is Unique for Each NoSQL Database
This is another area that is really confusing with NoSQL. Each of these NoSQL databases has its own query language. This is really challenging for developers who used to work with relational databases since SQL could be applicable across many relational database implementations with minor differences. With NoSQL, you have to refer to the documentation to understand the specific data types that are supported, query and feature limitations.
Why is it an important point to consider with NoSQL databases is the consistency models they support. Although some of these databases support strong consistency, others could be limited to eventual consistency. Depending on the type of query, the consistency support also could vary, whether its a read, write or an update. Querying is only possible with key attributes or using predefined indexes in contrast to Relational Databases where you can query almost from any attribute.
Using Both NoSQL and Relational
In my previous project, the web application feature required different query capabilities. If your application requires special support for High Throughput, Availability, Scaling of Storage, you can consider using NoSQL databases for the relevant area of use in addition to the relational database.
Over the past few years, the adoption of Microservices has also made it logical in using multiple database types depending on the required application capabilities. For example, you can consider using an In-Memory Key-Value NoSQL database like Redis for Session Storage, using a Relational Database for storing business entities, etc.
Rather than sticking with one database for all, it would be good practice in using different database types together to build applications.
Conclusion
The differences between NoSQL and Relational databases are many, although in this blog I discussed some challenges in using NoSQL there are many benefits in using NoSQL for some use cases. It all depends on the requirement of our work. Speaking about a few benefits includes the capability of handling large amounts of data for storage, scalability, flexible data collections &, etc.
Therefore, it is important to do sufficient background research, reach out for expertise and have an open mindset before using NoSQL because some of the practices that we have already learned on databases need to be unlearned, regardless of how experienced you are.