
Designing a DynamoDB database
DynamoDB is the nosql database provided by Amazon AWS. Here I will give a basic idea about designing a database using DynamoDb.
Basic Concepts
Table
Each database contains tables which is where our data will be stored. Tables in DynamoDB should be thought of more like a hash table containing many different kinds of items and not relational tables with strict schema.
Item
An item is an entry in the DynamoDB table. Each item can have any number of attributes as long as the maximum size of the item do not exceed 400kb. Each item must have a primary key which is how the item will be identified in the table.
Attribute
These are key value pairs contained in an item.

Note: It is not necessary that all items have the the same attributes. The only requirement is that every item must have a primary key. Any other attributes can be added or removed from each item independently.
Primary Key
Each item in the table is accessed by its primary key. The primary key is of two types:
- Simple Primary Key: A simple primary key is one containing just a partition key. The partition key will be hashed to determine where the item will be stored.
- Composite Primary Key: A composite primary key contains partition key as well as sort key. Partition key will be hashed to determine where the item will be stored. Sort key determines how the items will be ordered within it’s partition. This type of key is mostly preferred over simple primary key as it could be used to support a wide range of access patterns.
Note: Partition key is also called hash key. Sort key is also called range key.
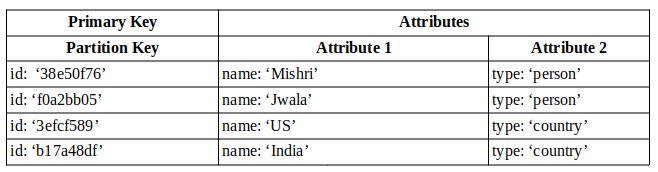
GSI
GSI stands for Global Secondary Index. They are tables derived from the base table in a DynamoDB database and is eventually consistent with the base table. A table can have upto 20 GSIs.

Note: It is not necessary that every item in the base table must contain the attributes that will be used as primary key in GSI. Only the items that contain the attributes that is defined as the GSI’s primary key will make it to the GSI. For this reason, GSIs are called sparse indexes.
Note: The primary key used in the base table is compulsorily projected into the GSI. For the other attributes, we can decide which attributes must be projected into the GSI.
LSI
LSI stands for Local Secondary Index. They use the same partition key as the base table but different sort keys. Think of it as a different ordering of items within the same partition. GSIs are preferred over LSIs.
Designing
Mindset
When designing table for DynamoDB, you will need to unlearn everything you learned about RDBMS and start with a clean slate. There is no rigid schema as in relational databases. You design the databases so as to support the different access patterns that your application requires. Also keep in mind that relational databases came at a time when storage was expensive. Therefore most relational databases are optimised for storage whereas nosql databases like DynamoDB are optimised for computing speed.
If you are anything like I was, you have a preconceived notion that nosql databases like DynamoDB are flexible. This is not exactly true. While nosql databases like dynamo are flexible in a way that there is no rigid schema, they are not flexible in terms of supporting different types of query patterns. RDBMS takes the win here as once the databases are designed, they can be queried in any number of ways (although it is slower).
The advantages that nosql databases like DynamoDB have over RDBMS is that is is very scalable and also that it is very fast if designed properly. The catch is that the speed and scalability comes with the limitation of restricted query patterns. Therefore it is extremely important to understand all the query patterns that our application would need and then design the database accordingly.
With all that said, let us get in to how to actually design a Dynamo database.
Table Design
This is where things start to go crazy. You are probably familiar with relational databases where you create different tables for different entities and then query them using joins. Dynamo doesn’t have anything like joins. Instead of creating different tables for different entities, it is recommended to create just one table for the entire application. You read that right. Just ONE TABLE!!. And then you can create indexes on that table to support the different access patterns that your application would require. If designed properly, even huge applications can make do with just one table.
Partition Key Design
As mentioned earlier partition keys are hashed to determine where each item will be stored. The partition keys should be chosen such that the partition space is spread out as much as possible. Care should be taken to avoid hot partitions. Hot partitions happen when a partition is overutilised. If the throughput of that partition exceeds the allowed throughput for the table, then the queries will be throttled. This should be avoided at all cost.
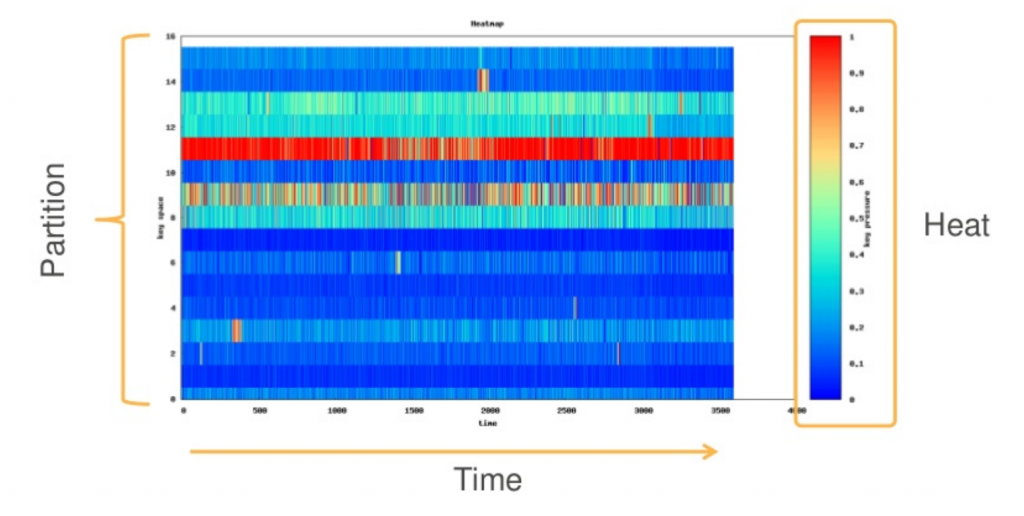
It is also good to avoid underutilisation of the partitions. This happens when the partitions are too spread out such that each partition is utilised way less than its provisioned throughput. Throughput will be used more efficiently as the ratio of partition key values accessed to the total number of partition key values increases. Although keep in mind that even an underutilised partition is way better than a hot partition. Hot partitions are evil and must be avoided at all costs.
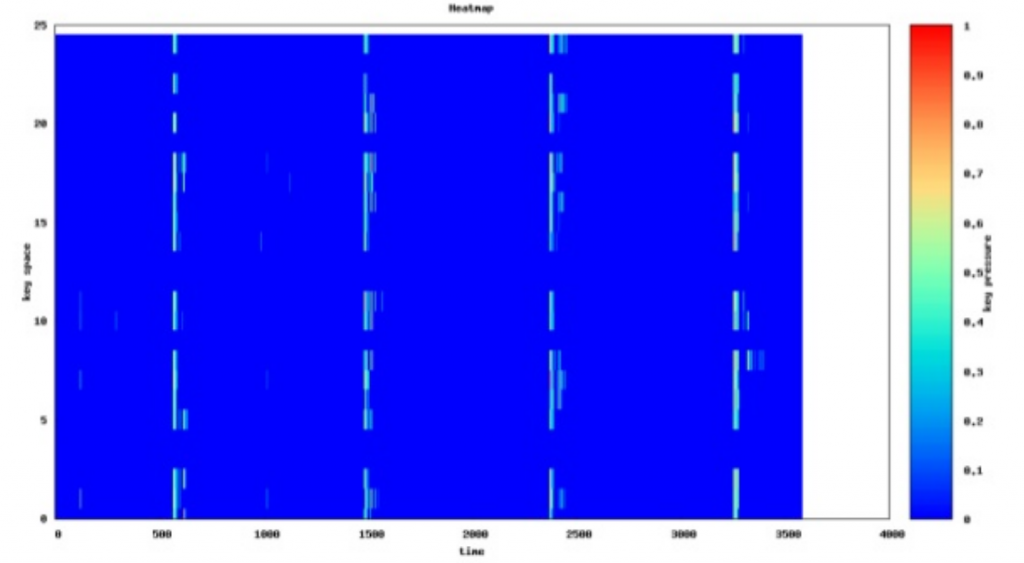
One more thing I would like to mention is that while using incrementing numbers may be common as primary keys when designing relational databases, they are not good for use in a nosql database like Dynamo as it affects scalability. For DynamoDB, it would be better to use something like UUIDs as partition keys.
Sort Key Design
When querying for items in DynamoDB, you need to give the partition key and then you can apply conditions (BEGINS_WITH, BETWEEN) on sort key. The sort key condition determines which all items will be read therby impacting the throughput consumed. When designing sort key, you must design it such that similar items group together.
Another important use of sort keys is when modelling hierarchical relationships which I will talk about later.
GSI
GSIs are indexes derived from table. You need to specify the attribute from the base table that will be used as partition key and sort key for the GSI. A table can support upto 20 GSIs. GSIs must be utilised to support alternative query patterns that our application would need. For the GSI example that we used above, it is possible to query all the list of all people or list of all countries.
Feel free to store many different kinds of data in the same attribute so as to support all the query patterns your application would need. This is a technique called overloading and using it you would be able to support more query patterns than you think possible with the same index. This is one of the extremely powerful technique you would use when designing a DynamoDB database. However I am not going into detail here.
One more thing to keep in mind when creating GSI is what all attributes you need to project. It is possible to project all attributes from the base table. However it is recommended to project only those attributes that would be needed by the queries you intend to support with the GSI. This way you can make sure that you do not consume too much throughput while reading.
Modelling Hierarchical Relations
Hierarchical relationships are modelled using composite sort keys. Composite sort keys are just a concatenation of different values to represent the hierarchy. The value that comes at the top in the hierarchy should be first in the composite sort key.
Let us bring back the table that we used above but this time I am going to add a new attribute to all ‘person’ items called ‘location’. Each location attribute value contains a concatenation of country_state as shown below.
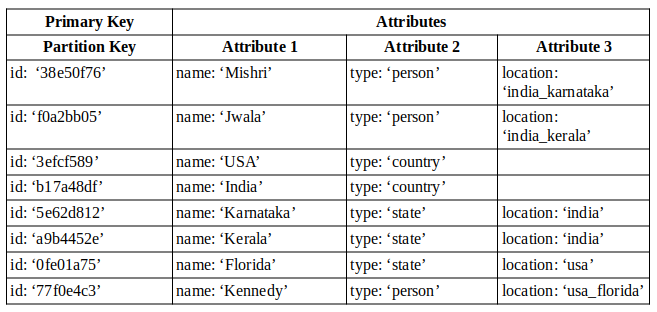
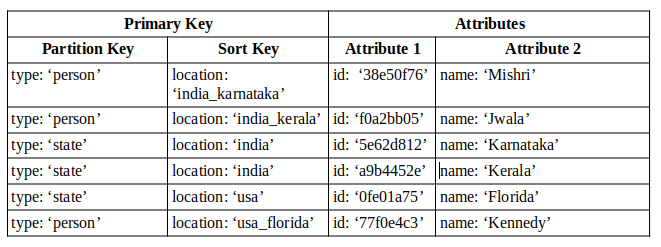
Now using the above GSI we are able to do the following queries:
- get a list of all states belonging to a coutry.
eg:'type'='state' and 'location' BEGINS_WITH('india') - get a list of all people belonging to a country.
eg:'type'='person' and 'location' BEGINS_WITH('india') - get a list of all people belonging to a state.
eg:'type'='person' and 'location' BEGINS_WITH('india_kerala')
Summary
- Database contain Tables. Tables contain items. Items contain attributes. Each item is identified by its primary key attribute.
- Have a clear understanding of the access patterns that would be required by your application and design the table to efficiently support those access patterns.
- Avoid hot partitions at all cost.
- Similar items must sort together.
- Use GSIs to support alternate query patterns that the base table cannot support.
- Use composite sort keys to model hierarchical relations
Conclusion
Everything I have said above barely scratched the surface of what DynamoDB is capable of. I have left out some important concepts like sharding, many-to-many relationships, time-series-data, versioning and a whole lot more. We have also not covered overloading in detail. However, now you are well equipped to dive deep and learn about all that DynamoDB has to offer. I hope my article was helpful in giving you an idea of what DynamoDB is and how you can start designing a Dynamo database for your next application.