
Elasticsearch
Here we are mainly looking into Why the search operation in elastic search is fast.
Elasticsearch is an open source distributed document store and search engine that stores and retrieves data structures in near real-time. It relies heavily on Apache Lucene, a full-text search engine written in Java (Lucene is just a library. To leverage its power, you need to work in Java and to integrate Lucene directly with your application).
Elasticsearch is:
- A distributed real-time document store where every field is indexed and searchable.
- A distributed search engine with real-time analytic.
- Capable of scaling to hundreds of servers and petabytes of structured and unstructured data
A document consists of different types of fields. Among these fields the text field uses an “Analyzer” that is, they are passed through an analyzer to convert the string/text into a list of individual terms/tokens before being indexed.
The two key parts in action here is, the Analyzers and Inverted Index
1.What is an analyzer
An analyzer is the one that transform the data stream in to tokens and store it in inverted index(will look into this later). There are many analyzers available and the default one is “Standard Analyzer”. Here we are mainly focusing on Standard Analyzer.
Any analyzer consists of two parts.
A) Tokenizer
The textbook definition is “A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens”. There are many tokenizers available. Standard Analyzer uses the Standard Tokenizer.
For Eg: When the text “Elastic Search is fast” goes through a Standard Tokenizer, it becomes [Elastic, Search, is, fast]
B) Token Filter
The textbook definition is “Token filters accept a stream of tokens from a tokenizer and can modify tokens (eg lowercasing), delete tokens (eg remove stopwords) or add tokens (eg synonyms)”. Out of many available token filters “Lower Case Token Filter” and “Stop Token Filter” are used in Standard Analizer.
For Eg: When the above tokens pass through these filters it becomes [elastic, search, fast]. “Elastic” and “Search” become “elastic” and “search” respectively because it uses the “Lower Case Token Filter” and “is” is eliminated because “is” is a stop word in English. Stop Token Filter uses English as the default language for stop words.
2. What is an inverted index
An inverted index is something similar to the last page of a book, that is the Index page. What we can see in that index page? See the image below. Looking at the index page we can easily find in which page or pages we need to refer for finding the details of a word.
Here looking at this page we can easily understand that the word ‘Apple Corporation’ is available in pages 203, 264 and 302.
An inverted index shown above is the same principle being used in elasticsearch as well.
A large text will be broken down into small tokens and that will be saved in index and when a search is performed, rather than checking whether the search text is available in all the documents we can directly refer the index and return the document.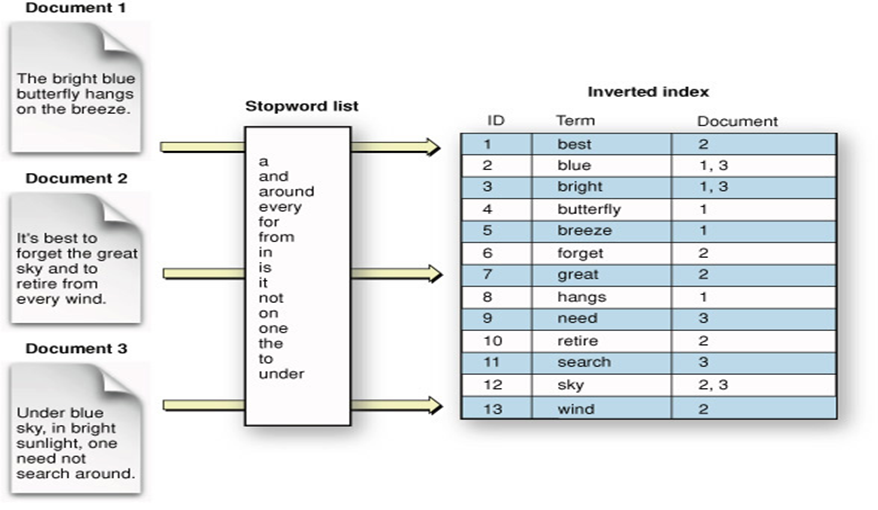
Referring the above image we can see that how these three documents have been tokenized and stored in the index. The stop words as well as the duplicate tokens have been eliminated.
So if we want to search for the word “sky”, we can directly query the inverted index and return document 2 and 3.
Elasticsearch is built to be always available, and to scale with your needs. Scale can come from buying bigger servers (vertical scale, or scaling up) or from buying more servers (horizontal scale, or scaling out). While Elasticsearch can benefit from more-powerful hardware, vertical scale has its limits. Real scalability comes from horizontal scale—the ability to add more nodes to the cluster and to spread load and reliability between them.